
Case Study
1 Introduction
As the quantity and diversity of data continue to grow, user data is becoming spread across a variety of third-party services catering to the needs of specific departments within a company (e.g., marketing, customer service, finance). Unfortunately, this places data in silos, fragmenting what should be a more unified user view.
With the advent of the cloud-native data warehouse has come the ability to collect data from disparate sources into one central repository and treat the warehouse as the “single source of truth”.
Data modeling and business intelligence or analytics tools built on top of the warehouse can now offer a consistent view of users. However, mapping this data back into the same third-party tools to impact day-to-day operations is still a huge challenge. In other words, there is a lag between insights and operations.
1.1 What is Tapestry?
Tapestry is an open-source orchestration framework for the deployment of user entity data pipelines.
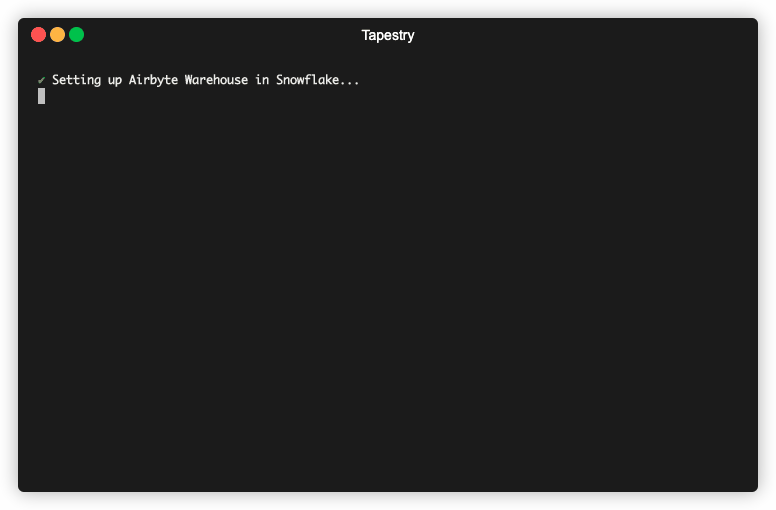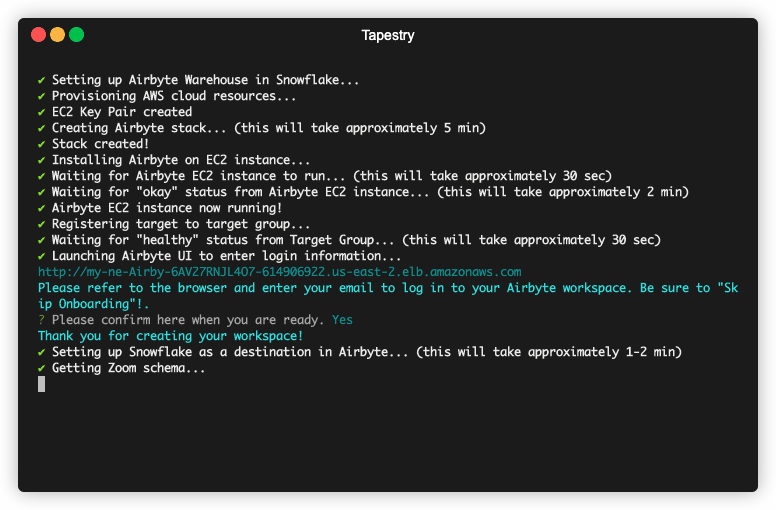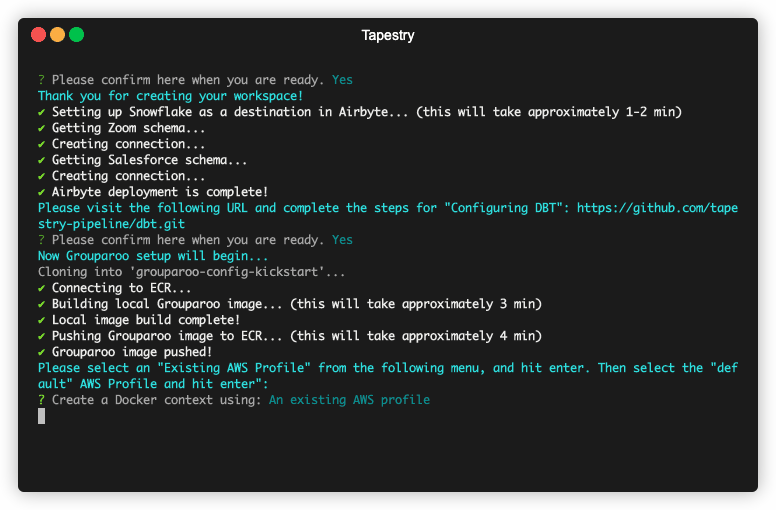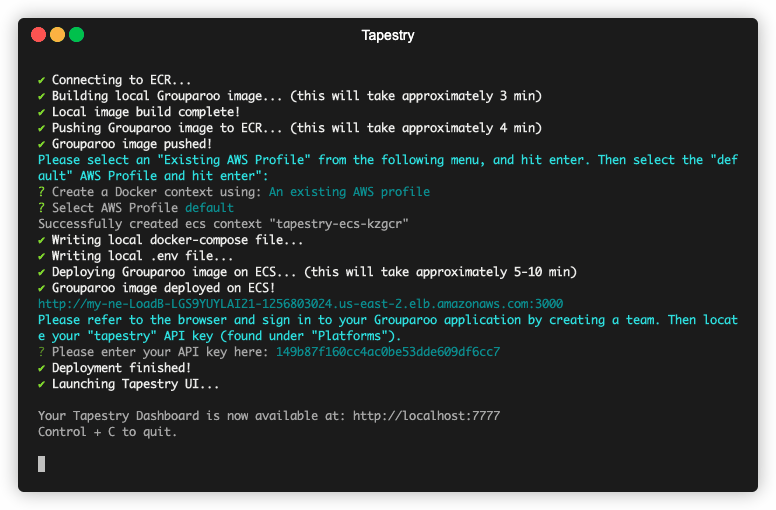
Tapestry allows developers to easily configure and launch an end-to-end data pipeline hosted on Amazon Web Services. With Tapestry, your user data pipeline will be automatically deployed and ready to ingest data from all your sources, store and transform that data in a warehouse, and sync it back to your tools for immediate use.
To illustrate just exactly what Tapestry does, let’s use the example of a company named Rainshield.
1.2 Hypothetical
Rainshield is a company in the umbrella space, with a thriving e-commerce store that is quickly gaining traction amongst a larger user base. This has attracted the interest of investors, and they’ve raised funding that has allowed them to expand.
The small team that started Rainshield is no longer able to wear all hats. They are beginning to staff larger departments, such as sales, marketing, and customer support, to manage the influx of new business they’re experiencing.
1.3 SaaS Bloat

As the business evolves, Rainshield begins to utilize various SaaS tools to engage with their user base in new ways and to meet the daily operational needs of different departments.
For example, they begin to use Stripe to handle all of their online transactions. The company’s sales team has started using Salesforce to organize and track their leads, and the Rainshield customer support team is now incorporating Zendesk to help with managing all of the support tickets that are being generated. The marketing team is even planning on hosting a Zoom webinar on a design-your-own umbrella product they are about to unveil soon!
Prior to this growth, user data was largely managed in the production database. However, these teams are not only requiring different views of this data to accomplish their goals but are also creating new sources of user data as they interact with customers through a variety of platforms and tools.
1.4 Data Silos
While these third-party SaaS tools cater to the needs of each department well, user data is beginning to proliferate the organization, in terms of both the data produced and collected. Data is becoming scattered across the different tools each team is using.
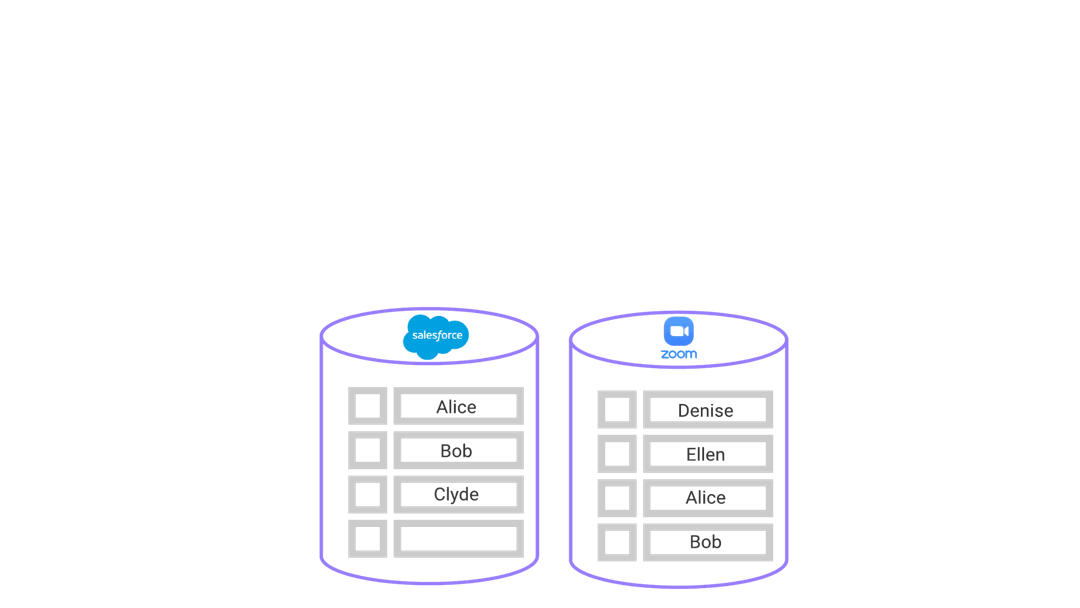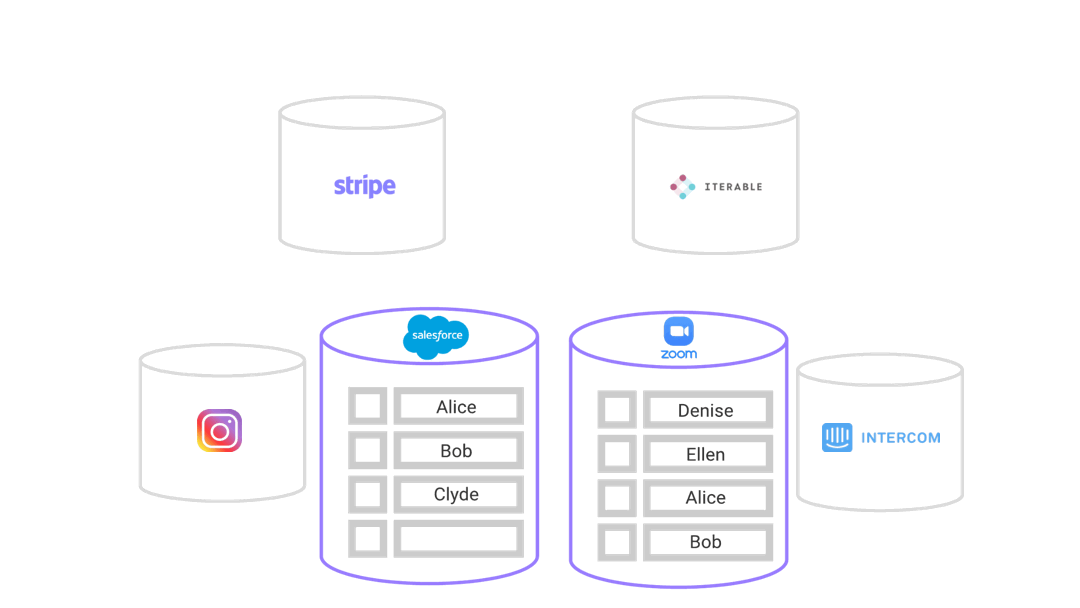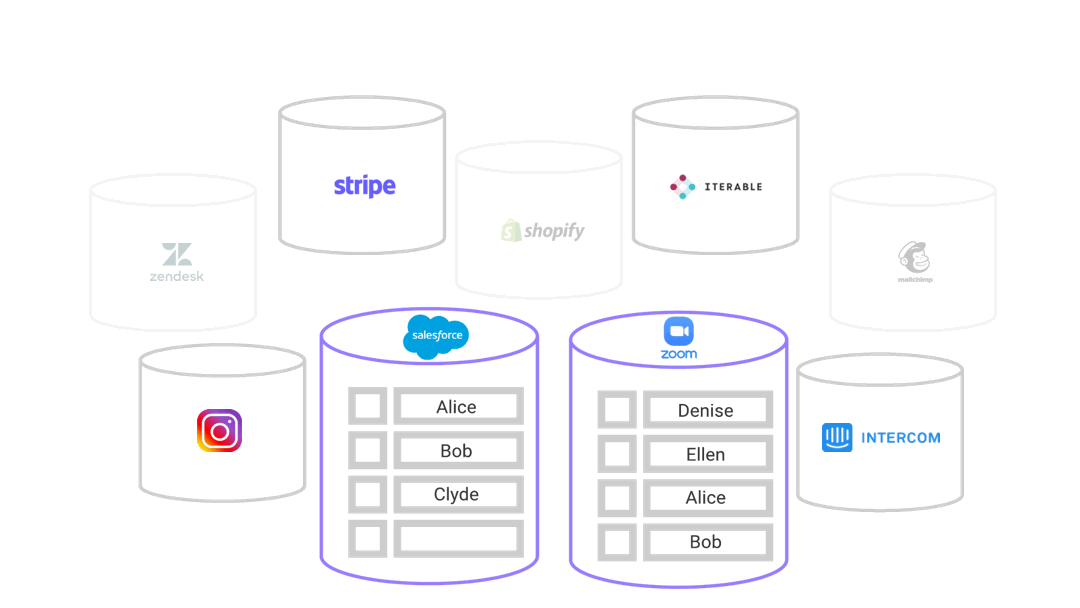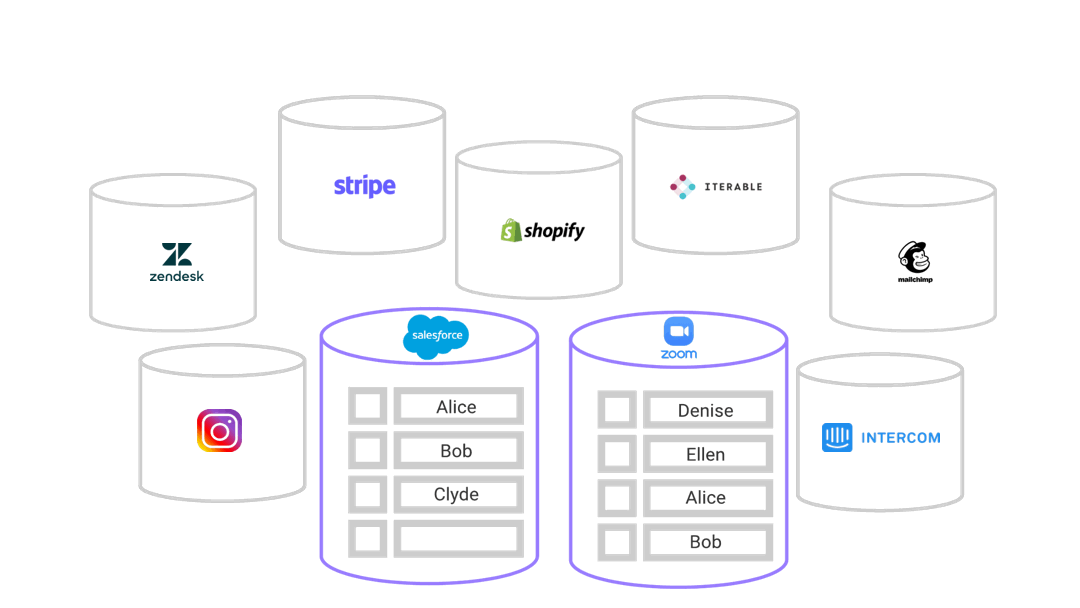
These tools were not designed with integration in mind, and it is becoming more challenging to have a unified understanding of a single user and how they are interacting with Rainshield and its product. Each tool has access to only a portion of the customer’s information, but not the whole picture.
These SaaS tools, that have increased productivity, have now become known as data silos. Data goes in, but it doesn’t come out.
The industry agrees that this is a challenge:

1.5 User Data
To better understand the ramifications of data silos, let's turn back to our company Rainshield.
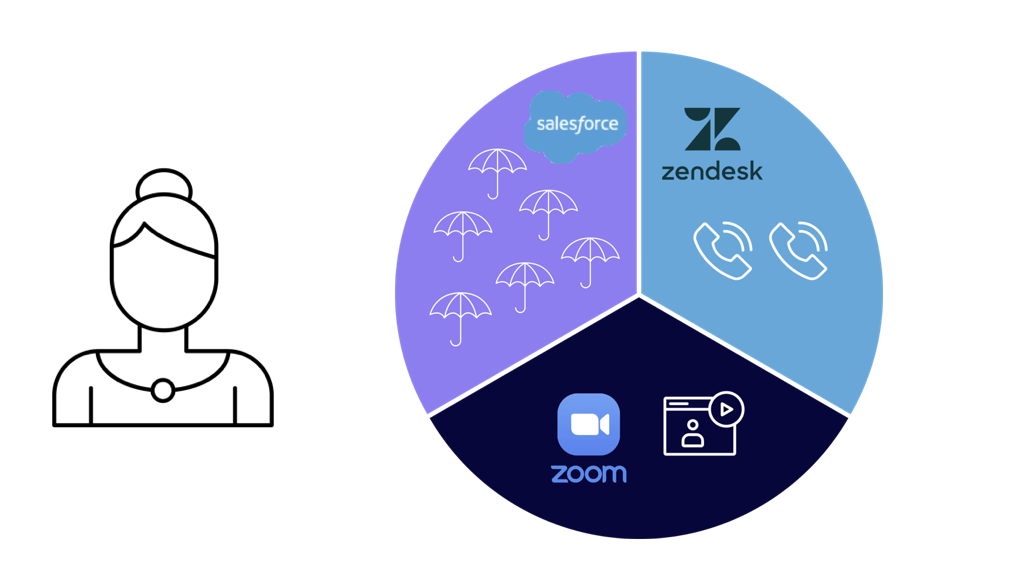
Meet Susy, a Rainshield customer. According to her profile in Salesforce, Susy has purchased six umbrellas for her friends and family. However, Zendesk indicated that she called two times complaining about the color of some of her umbrellas. Susy is excited about picking her own umbrella color and is signed up to attend the Zoom webinar unveiling the new design-your-own product. When this data about Susy lives in different tools, it becomes difficult to access a composite picture of Susy.
1.6 Analyzing and Leveraging User Data
Susy's data lives in only three tools, but it's easy to imagine that Rainshield could use many more tools that capture different pieces of data for other users. They might have thousands of different customers buying their umbrellas, some of whom fit Susy’s exact profile. When data can be collected in one place, Rainshield can begin to see patterns among these users.

But even with this user data gathered for analysis in one place, how can these insights be used to impact day-to-day operations?
Let’s say Rainshield would like to use what they know about Susy and other customers that match her profile in an attempt to increase sales. They believe that this group of users will be especially interested in the new umbrella colors that Rainshield just rolled out, and they would like to prompt these customers with a custom chat message via Intercom the next time they log on. But before this desired action can take place, Rainshield still needs to provide Intercom with this specific list of customers. In other words, making insights actionable still requires work. Rainshield needs to map relevant user data to Intercom in the particular format that Intercom requires. This process can be thought of as data syncing.
So let’s take a step back and recap the obstacles that Rainshield and companies like it are facing. Important user data is being trapped in silos as the quantity of Rainshield’s SaaS tools increases.
Companies would like to:
- Aggregate data from these disparate third-party sources into one location for better analysis.
- Sync relevant data to other third-party destinations to drive operations based on their findings.
1.7 Challenges of User Data Integration
There are several challenges of this type of data integration. User data stored in SaaS applications is similar in structure to the data we see in traditional relational databases. However, unlike relational databases, data in SaaS applications cannot be accessed with a simple query.
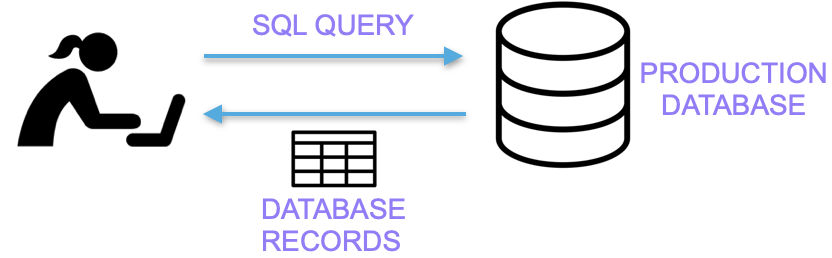
Instead, this data must be retrieved via unique REST APIs, making it difficult to determine how to communicate with each tool.
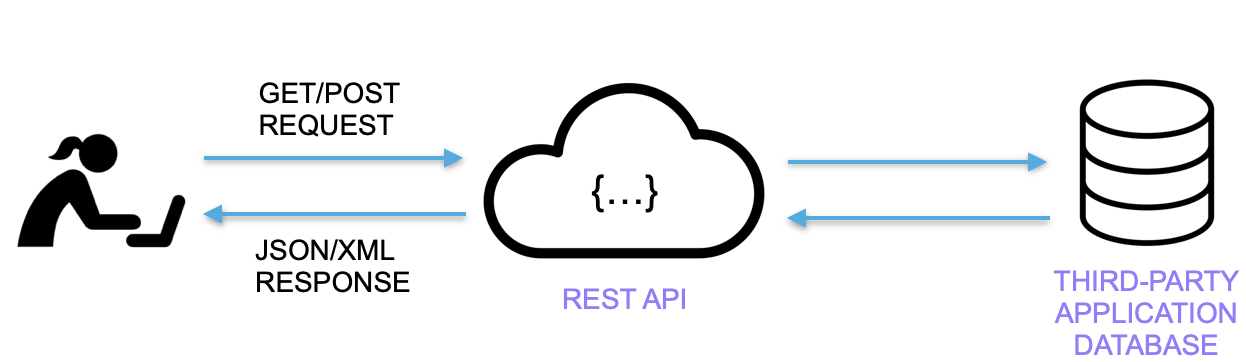
Furthermore, factors such as limited documentation, rate limits on API requests, managing potential network errors, and ever-changing API schemas can make transporting large amounts of data a challenging and slow process.
2 Existing Solutions
There are four main options for integrating data between third-party tools:
- Manually move files between tools
- Use pre-built connectors
- Create custom connectors
- Build a complete data pipeline
2.1 Manually Move Files
Let’s talk about the first option at Rainshield’s disposal, manually moving files between tools.

Let’s say that Rainshield wanted to make sure that Salesforce had all of the contacts from the Zoom webinar revealing the new design-your-own umbrella.
They could simply export the list of webinar attendees from Zoom to a CSV file and then import that file into Salesforce. However, this might result in duplicate data and could become tedious if you had to do this task often.
2.2 Use Pre-built Connectors
Another possibility would be to use a company that creates these connectors for you, like Zapier. After inputting some information about their Zoom and Salesforce accounts, Rainshield can choose from a menu of pre-built connectors to set up the flow of data between them.
This, however, would not allow much flexibility regarding which parts of the data would be shared between the two apps. There may still be duplicate data, or the selection of apps available may not fit all use cases.
Another type of pre-built connection exists in some tools' settings. For example, Zoom can integrate directly with Salesforce by simply configuring your settings to export your data. This isn’t always the case though, and more than likely, Rainshield will not find connectors for every tool it uses.
2.3 Create Custom Connectors
The third course of action is that Rainshield could designate one or two software engineers to begin building custom connections to pipe data directly into all of the tools they use. The benefit of this option is you can flexibly choose what data to send. However, these engineers would have to research these tools' APIs and write connectors not only to extract data, but also to sync data as well.
This might not be too bad if the number of tools the company used was very small. For example, if Rainshield only needed to connect Zoom and Salesforce with Mailchimp, then they may only have to write a few connectors to ensure they all shared the same data.
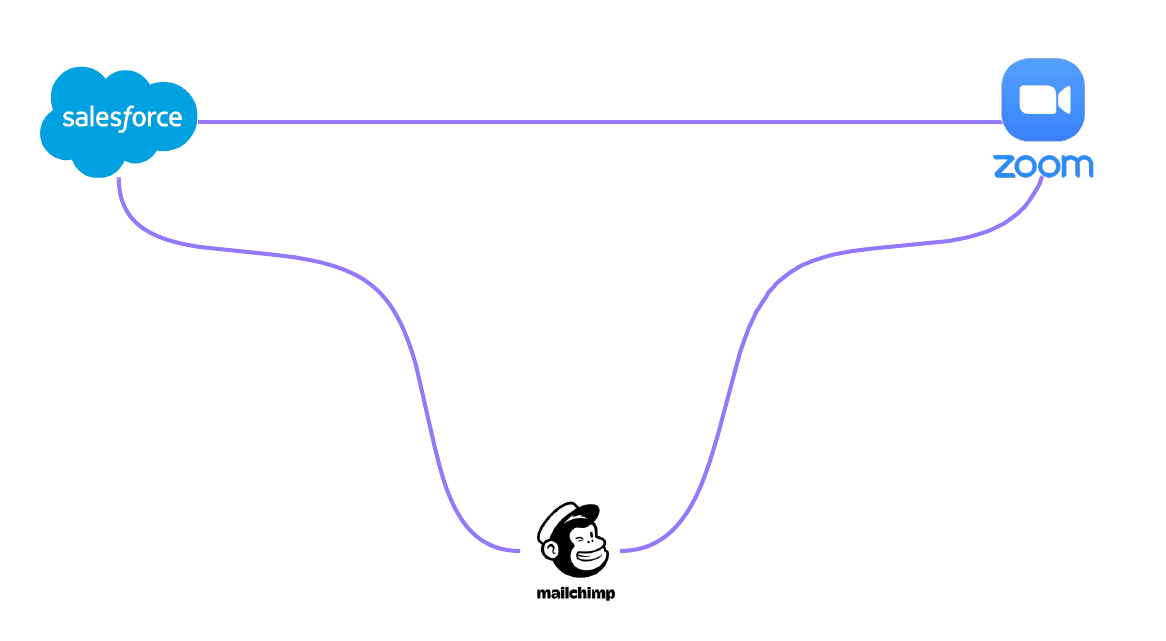
However, if your company already uses several tools or plans on growing in the future, this can quickly get out of hand. And this is to say nothing of the fact that these connectors would also have to be maintained.
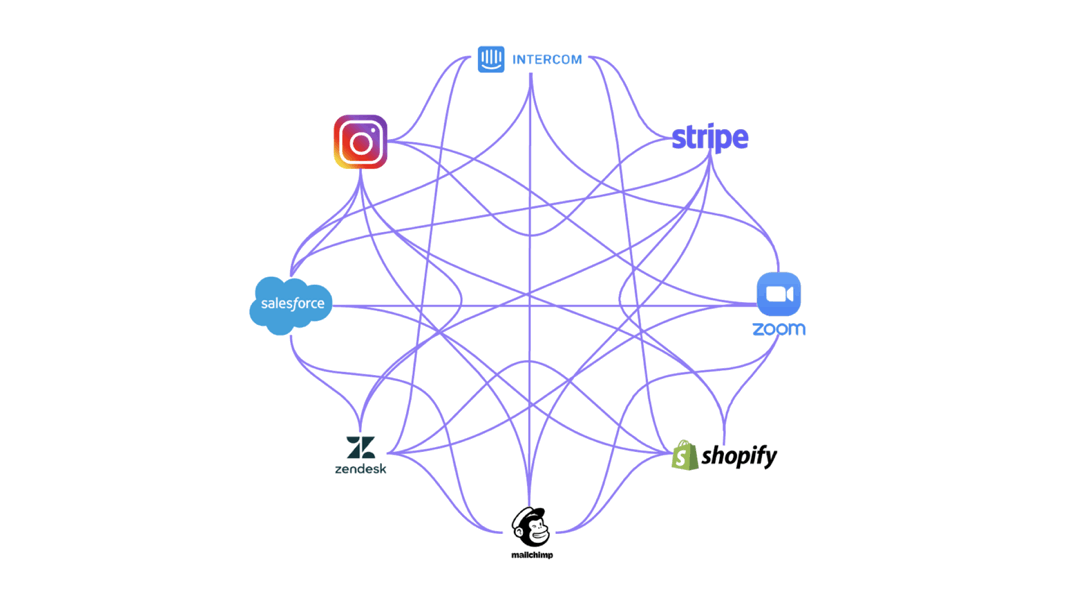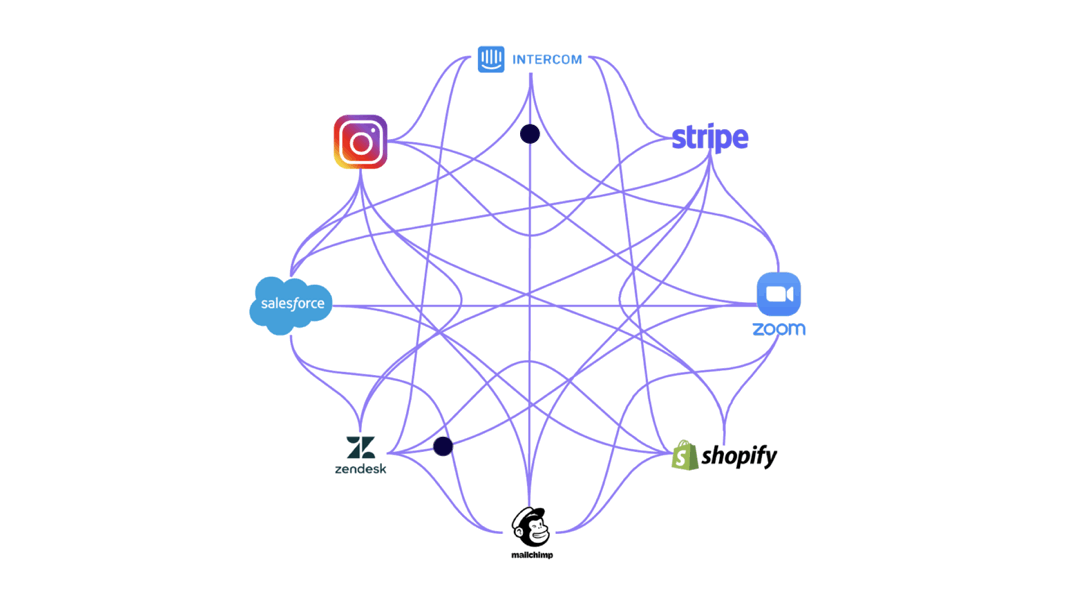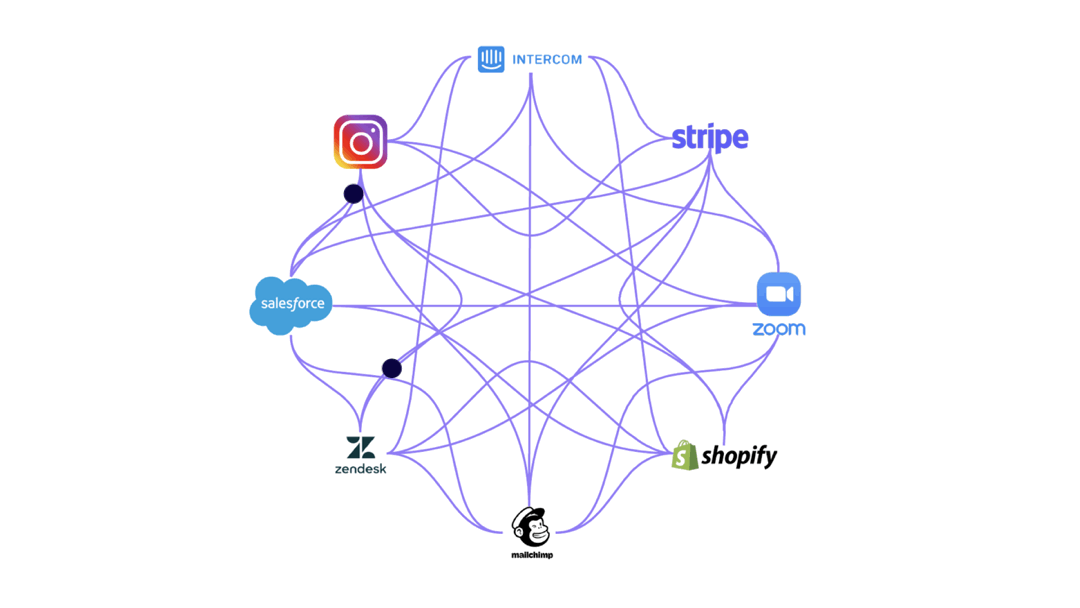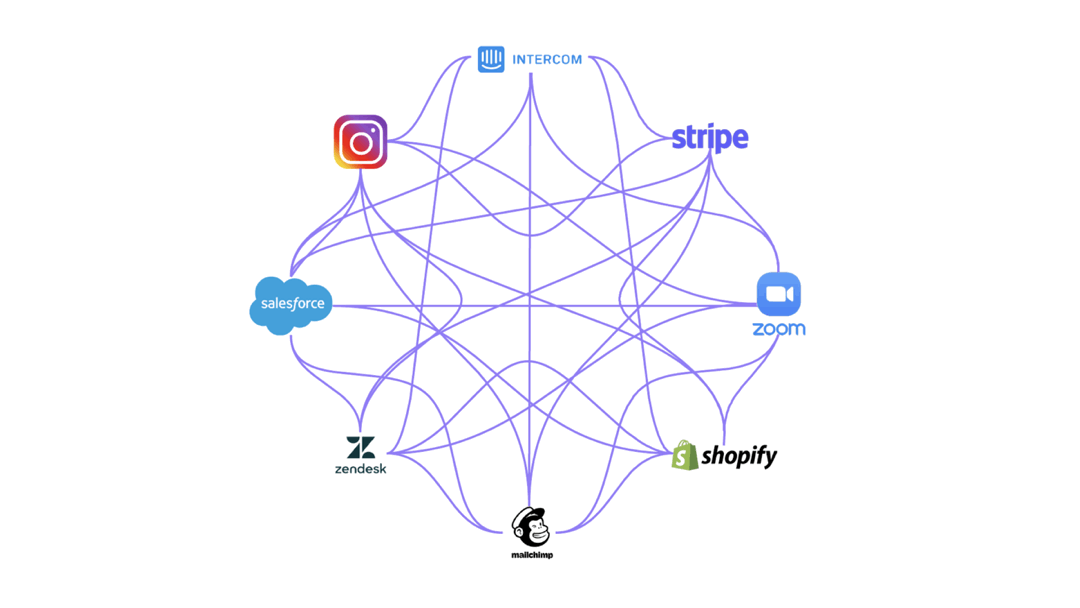
If one API changed, every tool that connected to it would also need to be changed. And the reality is that even small companies use anywhere between 10 to 50 tools. That would require a lot of valuable engineering time.
2.4 Build a Complete Data Pipeline
The best and most complete solution is our last option, implementing an end-to-end user data pipeline, with a cloud data warehouse at the center.
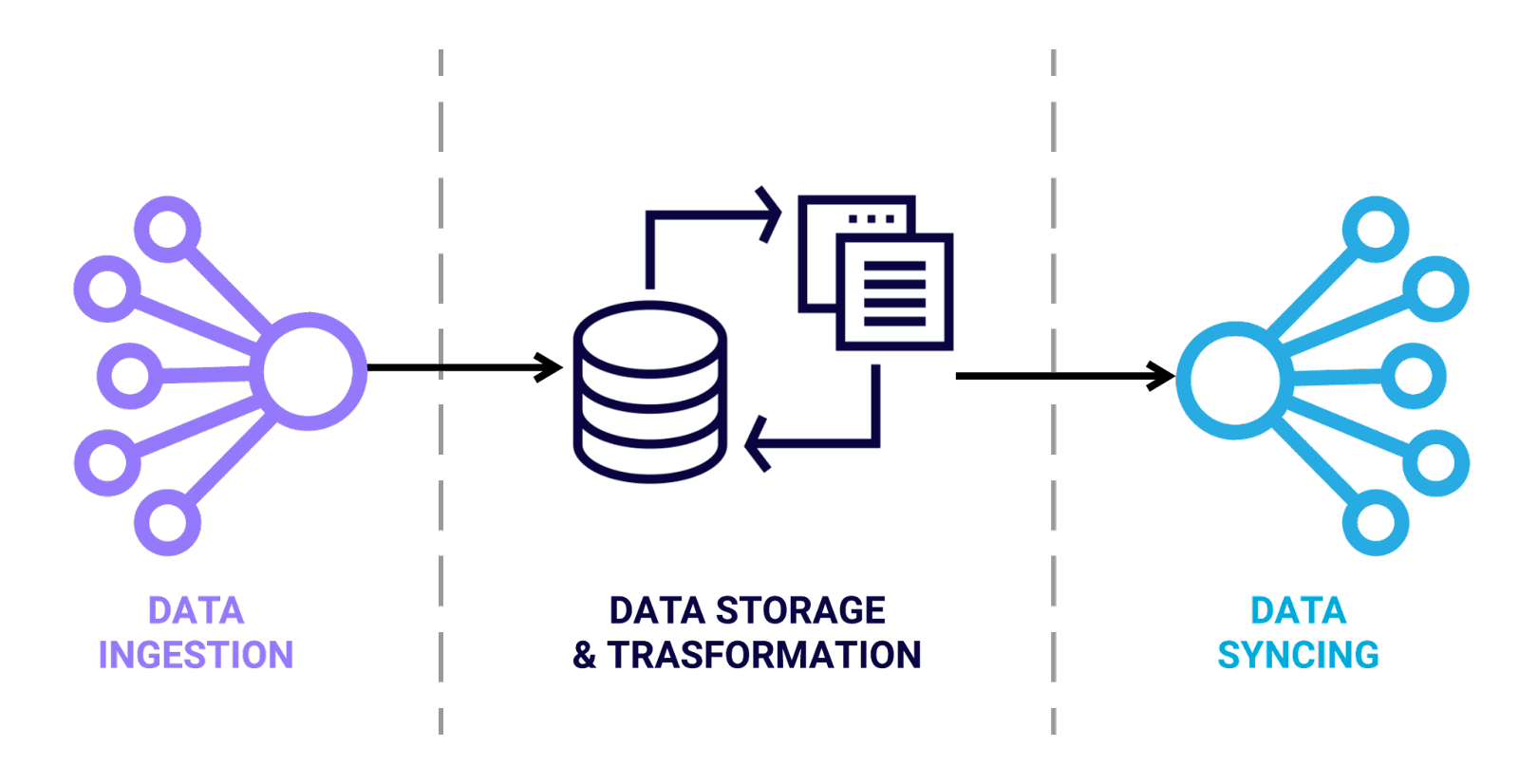
From an engineering perspective, this approach allows access to data ingestion and syncing tools that remove the headache of working with third-party APIs, while also providing you with the flexibility that custom connectors offer, i.e. you choose exactly what data to send.
Benefits of Warehouse-Centric Pipelines
Placing a cloud warehouse at the center of your pipeline also provides several other benefits.
Cloud data warehouses:
- Allow for the storage of large amounts of data with very little infrastructure management and instant scalability.
- Serve as a single source of truth if two departments ever had conflicting data.
- Enable the use of data modeling and analytics tools, which can aid in making important business intelligence decisions.
- Offer the ability to combine and filter data from multiple sources in order to sync with another destination.
This warehouse-centric pipeline helps aggregate all of your data into one accessible place so you can create unified models and sync them to the tools your teams need.

2.5 Data Pipeline Solutions
When deploying this type of user data pipeline, the two primary options are to use a proprietary hosted solution, such as the one offered by the company Rudderstack, or to use open-source tools to configure your own pipeline.

The self-hosted option allows for the inclusion of fully open-source tools and grants you full ownership over your pipeline infrastructure. This means you can customize it any way you like. But this solution doesn’t have any out-of-the-box features and would require a substantial amount of engineering time.
Rudderstack, on the other hand, only offers open-source event streaming, and also requires you to use their infrastructure, leaving you with little control. However, they provide a ton of features and also abstract away all of the infrastructure provisioning and management, making it extremely easy to deploy a user data pipeline quickly.
Challenges of Pipeline Deployment
Building your own pipeline requires an extraordinary amount of time and effort to set up, provision, and configure.
You need to make many different decisions about which tools to use for data ingestion and syncing and which warehouse to select, and that’s not even mentioning all that goes into provisioning and maintaining pipeline infrastructure. To say the least, this is an extremely complex process.
3 Tapestry's Solution

Tapestry is for developers who want full control over their data infrastructure, but without having to provision that infrastructure themselves. Tapestry is a completely open-source framework that automates the entire pipeline deployment process. We do not, however, have very many out-of-the-box features.
Tapestry weaves together all of the necessary resources to create an end-to-end user data pipeline, automate the setup and configuration, and let you spend your valuable time doing something more important.
3.1 What Tapestry Automates
So if you are thinking about rolling your own self-hosted solution, but want to simplify the deployment process, we might be able to help.

Tapestry automates many steps and creates a number of resources for each phase of the pipeline. As you can see, deploying your own user data pipeline would require at least 71 steps and the provisioning of 49 resources between AWS and the data warehouse.
4 Tapestry's Architecture
This is what Tapestry’s pipeline looks like once deployed.
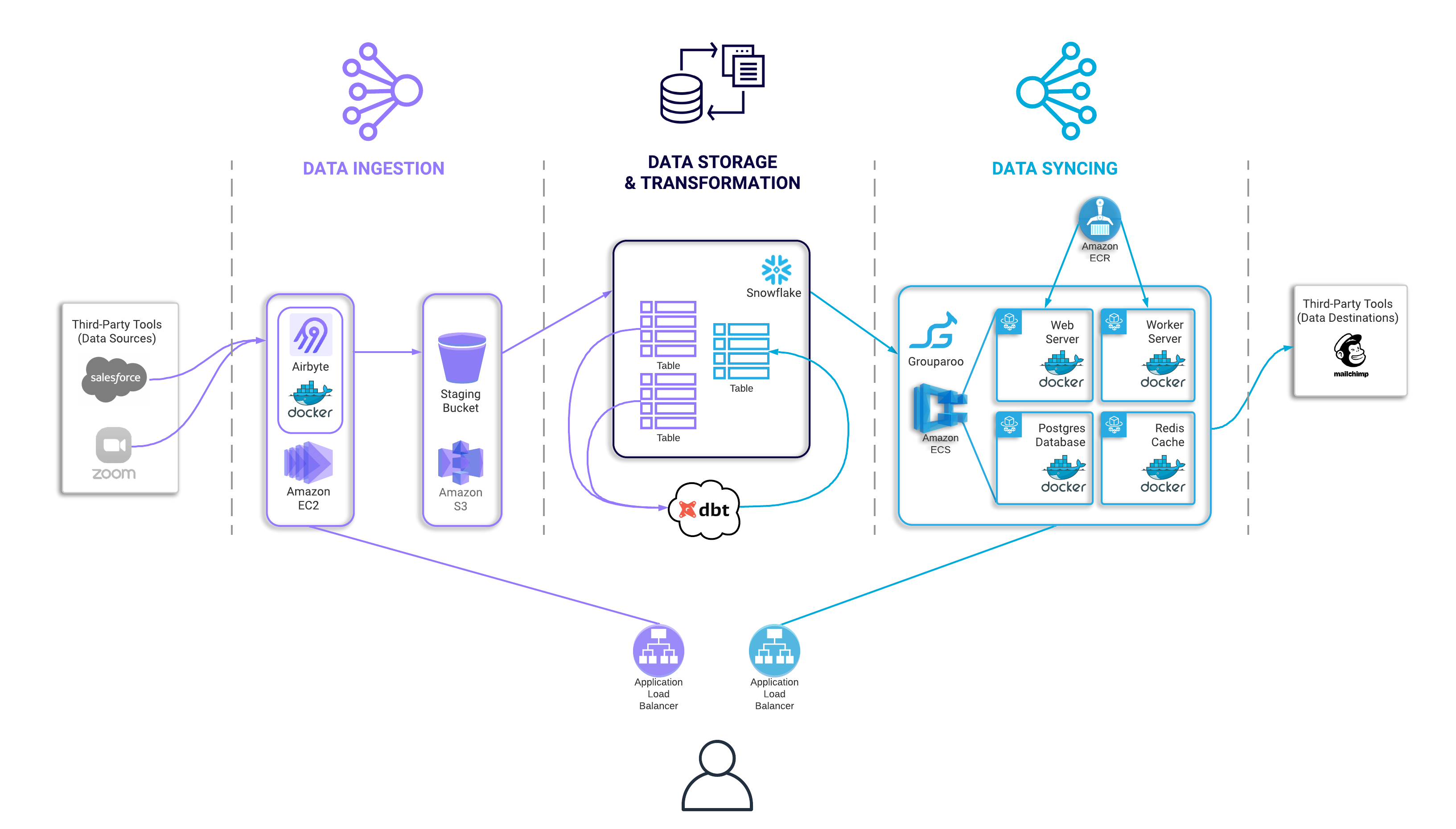
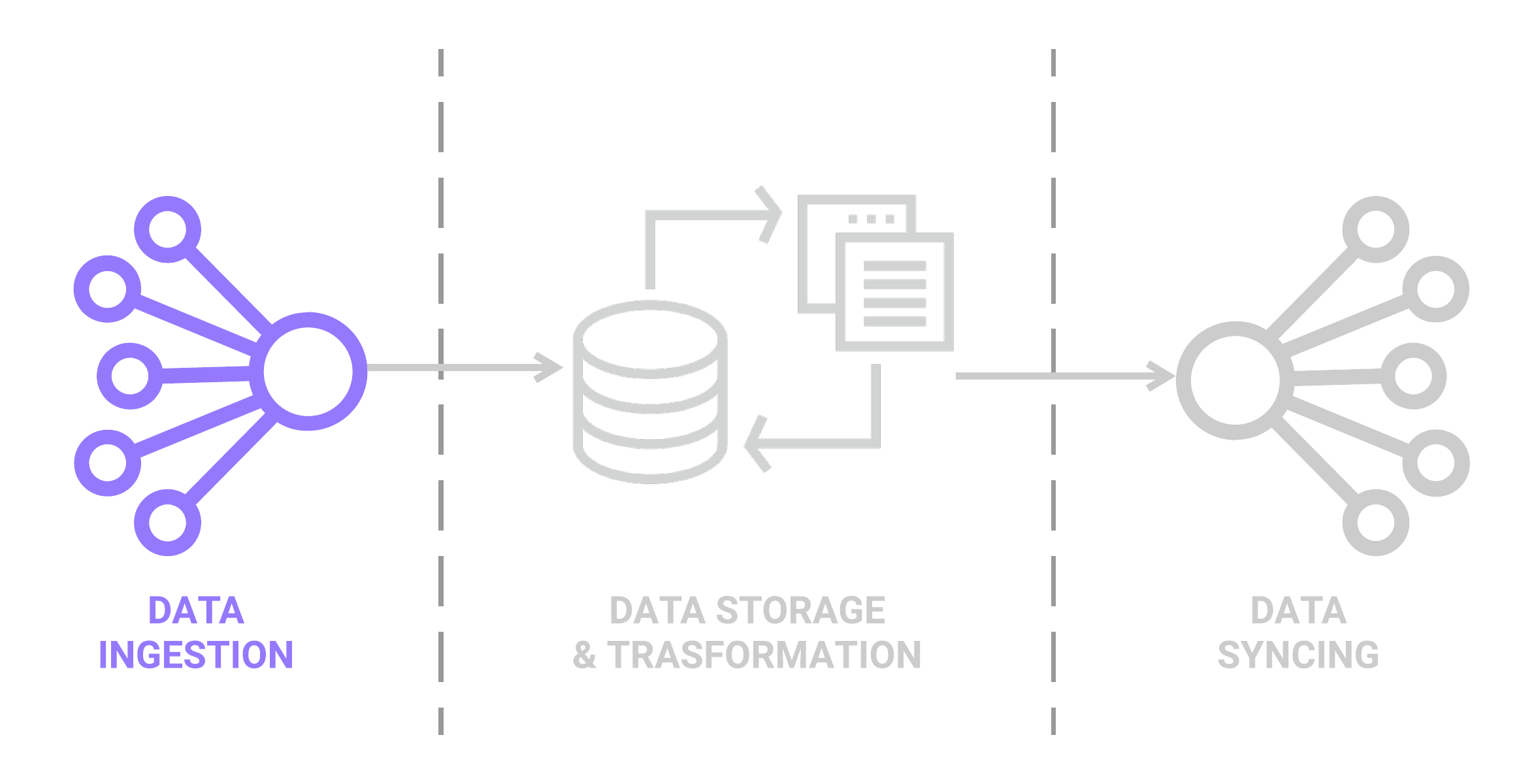
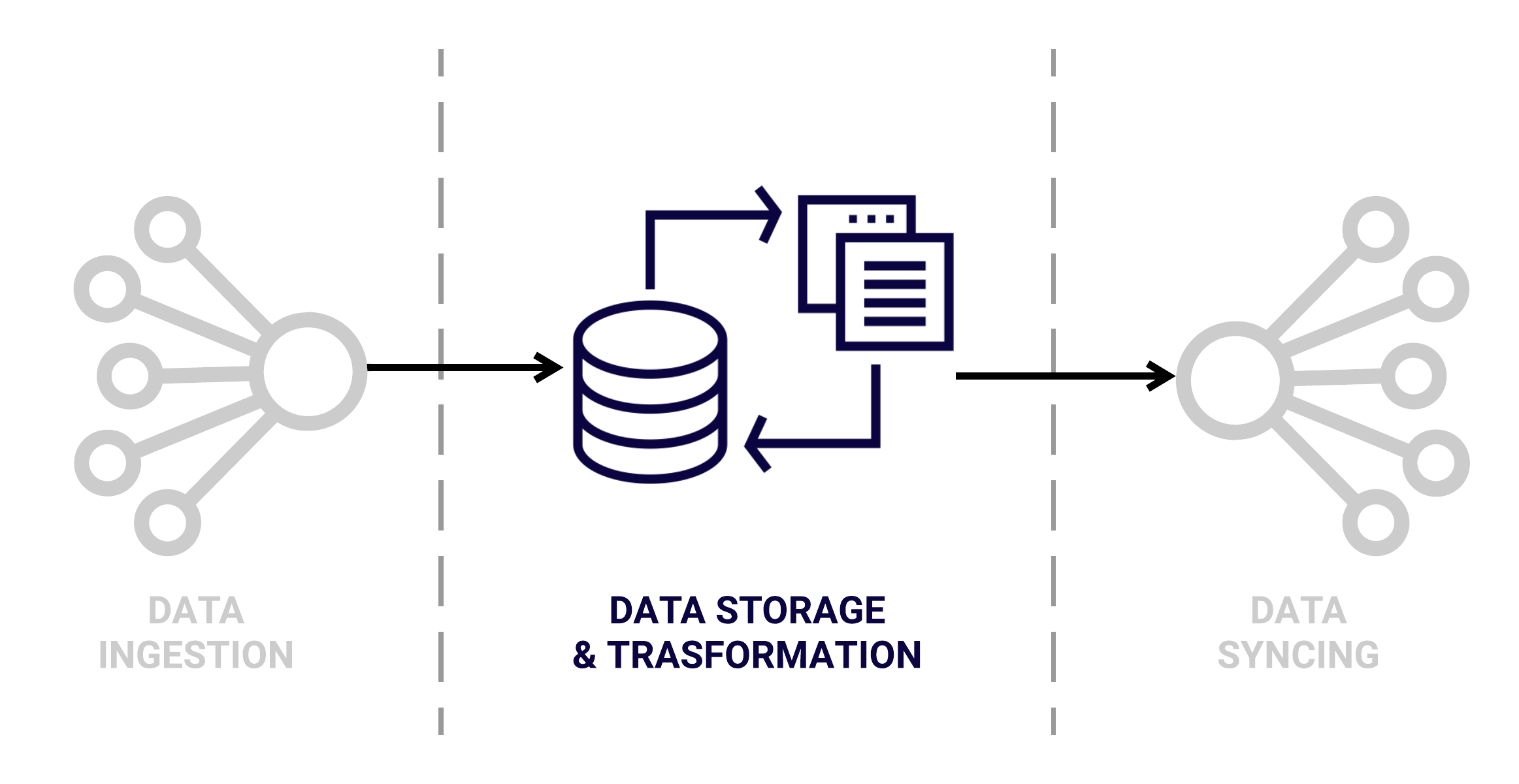
Before diving into the specifics of this architecture, let’s quickly revisit the three phases of our pipeline: Ingestion, Storage & Transformation, and Syncing.
The ingestion phase is where data is extracted from various sources and is loaded into a data warehouse. Once in the warehouse, this raw data is then stored and is available to manipulate or transform in any way needed. Often transformation is needed at this step so that the data can match the schema of the final destination. The last phase is syncing this data into external tools that can then perform designated actions.
4.1 Data Ingestion
An effective data extraction tool will contain and manage a library of API connectors, specific to each source. This management of connectors abstracts away the maintenance required to grab data from ever-changing API endpoints. In addition, this tool should allow for scheduling data extraction and keeping track of global state so that only new data is pulled.
Flow of Data: ETL vs. ELT
In order to make a decision regarding data ingestion, it’s important to consider the path by which the data travels.
In the past, storing data was an expensive endeavor. This made it more cost-effective to perform any sort of data transformations before loading the data into a database or warehouse to reduce the amount of data being stored. This approach is known as Extract-Transform-Load, commonly referred to as ETL.
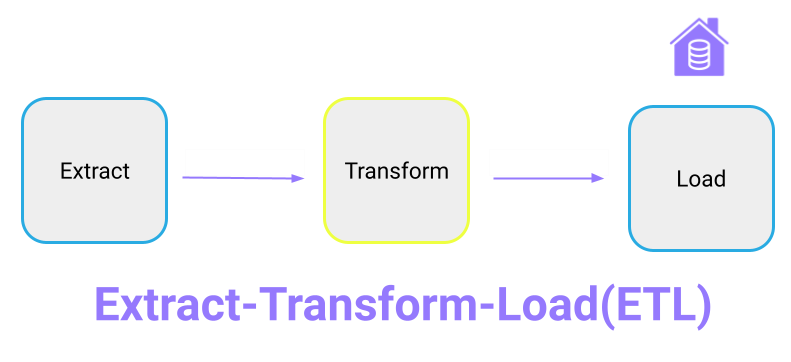
However, with the advent of cloud data warehouses, the costs of storing data have decreased dramatically. This makes it more feasible to store all of your user data as raw data and to perform any transformations at the warehouse level to fit a variety of analytic and operational needs. And since transformations aren’t required first, data can be loaded extremely fast. This approach is known as Extract-Load-Transform, or ELT.
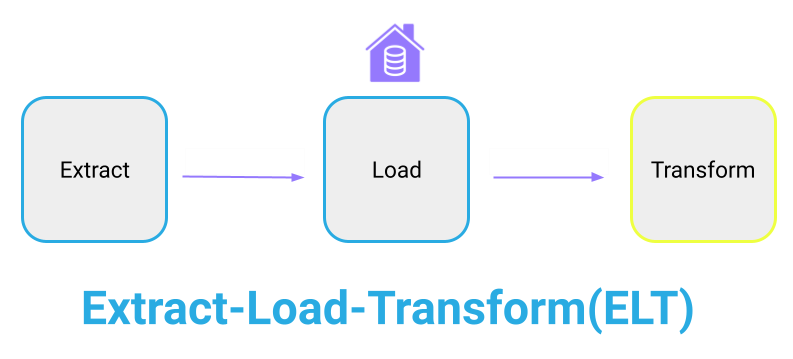
Since it was vital for our pipeline to have access to all of the raw data we chose to go with an ELT solution.
Data Ingestion Tool: Airbyte

While many data ingestion tools are available, like Fivetran, Stitch, and Meltano, we ultimately went with Airbyte. We liked that it was open-source, had standardized API connectors, a robust UI, and strong community support.
Data Ingestion: How We Deploy Airbyte
Using Airbyte, we’re able to extract raw data from many third-party tools through its library of managed API wrappers, covering the E and L steps of ELT. Both the Airbyte application itself, as well as each of its connectors, all run on their own individual Docker containers. Airbyte provides the Docker image to deploy their application, and Tapestry configures the warehouse as a destination for Airbyte via a series of API calls.
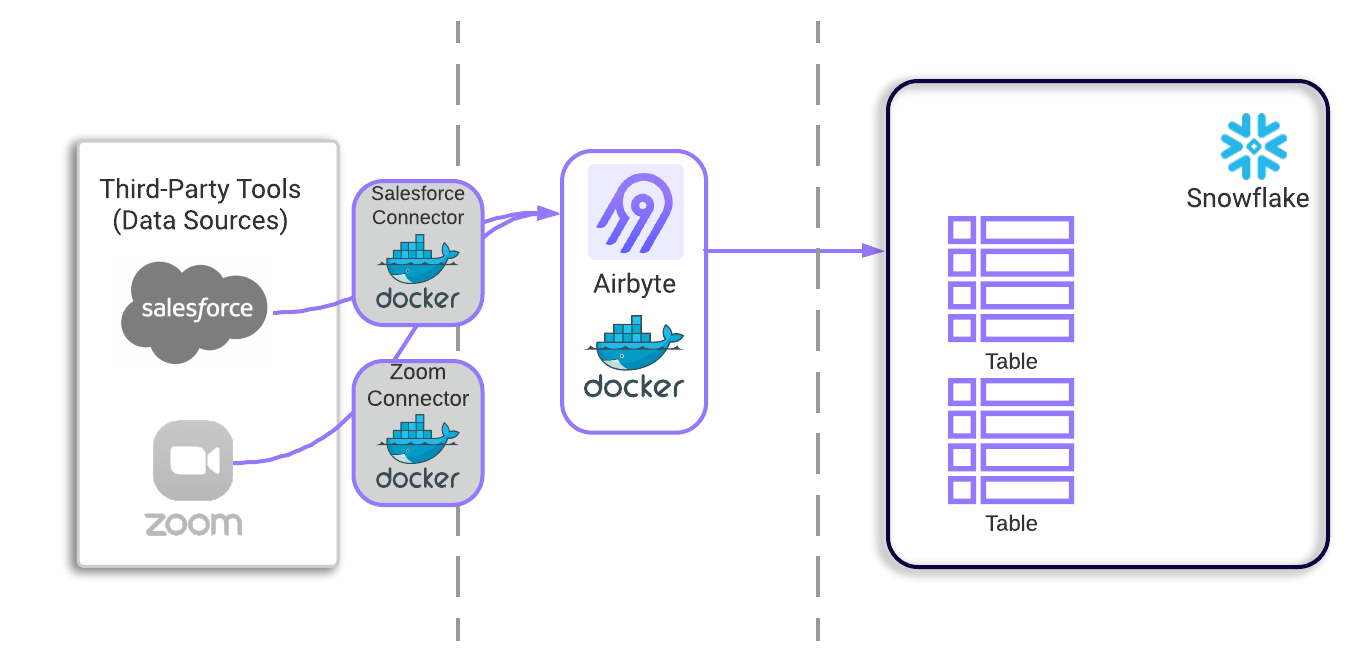
Essentially the main application’s container needs to be able to create new Docker containers as users set up more and more connections. Due to this necessity, Airbyte recommends the use of an AWS EC2 instance as a virtual private server for hosting.
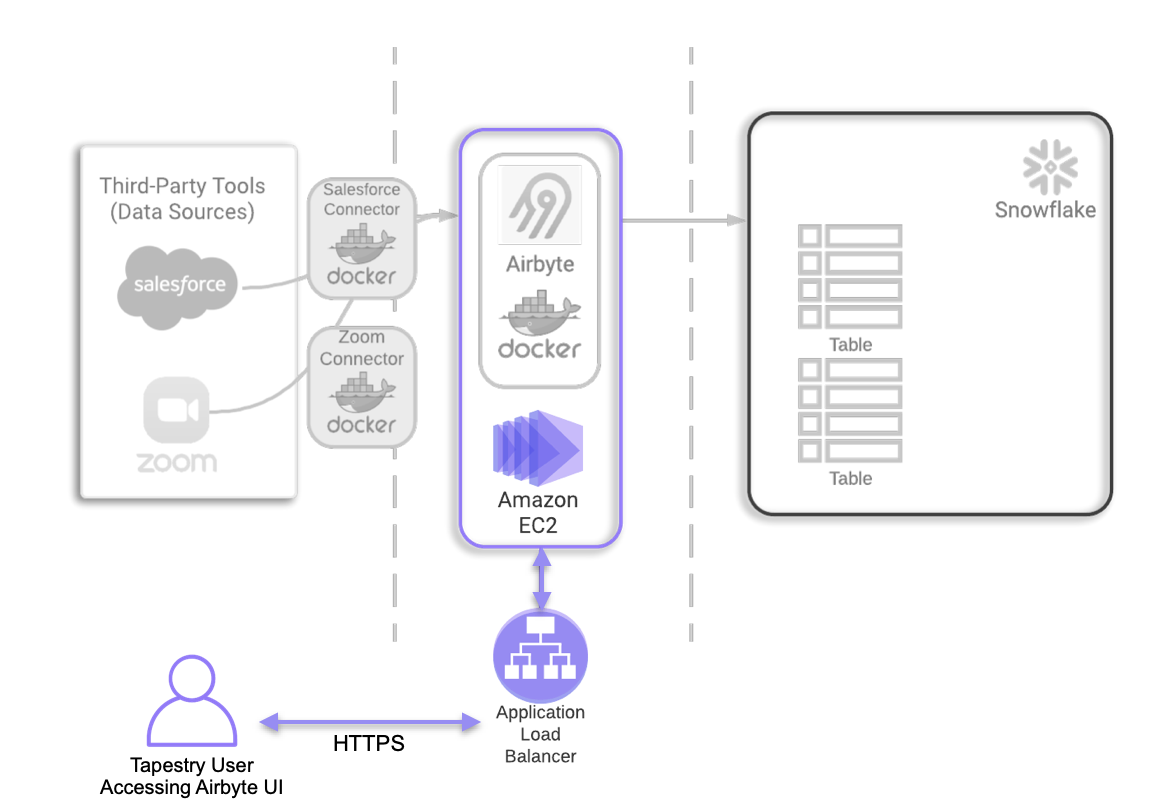
While we might have preferred to use a container orchestration service to horizontally scale the computing resources used by each container, an EC2 instance still allows for vertical scaling of the entire instance.
Placing a load balancer in front of Airbyte means traffic cannot reach the EC2 instance directly. Network traffic must first pass through the load balancer before it’s routed to the Airbyte instance. This allows us to take advantage of additional security measures and keep the IP address of the actual instance hidden. This keeps the instance safe from any port scanning attacks and also takes advantage of AWS’s built-in protection from DDOS attacks.
4.2 Data Storage and Transformation
The next phase of a data pipeline is data storage and transformation.
Data Warehouse: Snowflake
We’ve already determined that at the center of our pipeline should sit a warehouse that is capable of handling large amounts of data from a variety of sources. Given our decision to host our tools on AWS services, a warehouse that could be seamlessly integrated with AWS was preferable. While there are many options for a data warehouse, such as Google BigQuery, Amazon Redshift, and Microsoft Azure, we chose Snowflake.

Snowflake can be built on most major cloud platforms, providing valuable flexibility. It also separates storage needs from computing, also known as query processing. This allows companies to take advantage of cost savings as well as enable us to scale those two responsibilities independently. Finally, Snowflake abstracts away the provisioning and maintenance of all the necessary resources for a cloud data warehouse.
Data Storage: Using a Storage Bucket
Initially, we attempted to load data directly into Snowflake from third party tools, but we found the data transfer to be particularly slow. This led us to investigate using a staging area with Snowflake and how this impacts data loading.
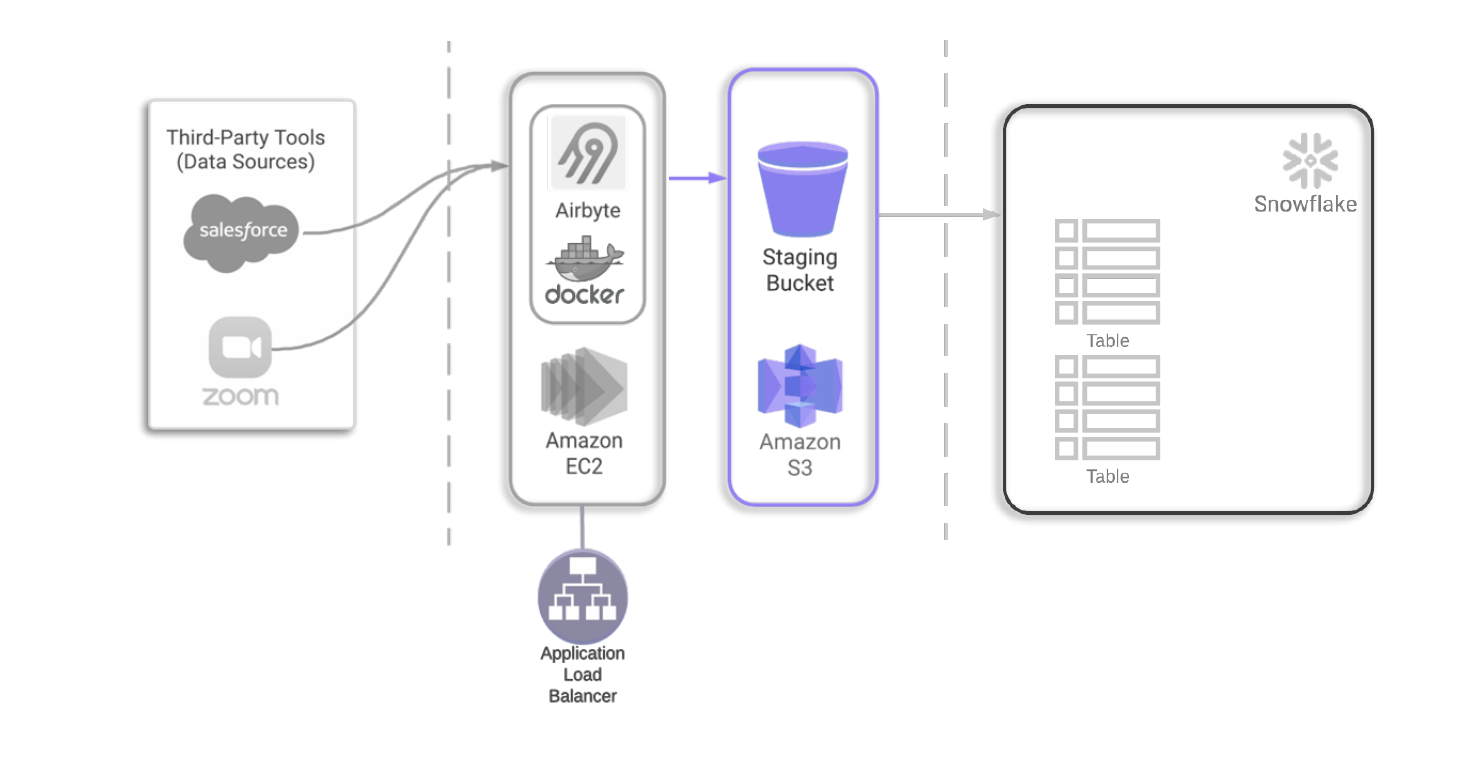
Without this staging area, Airbyte can only insert one row of data at a time into Snowflake, requiring numerous SQL INSERT commands to copy over an entire table. With the addition of a staging area, Airbyte can achieve efficient bulk data loading.
To implement this staging area, we provision an Amazon S3 staging bucket between our Airbyte instance and our Snowflake data warehouse.
Data Transformation Tool: DBT

A data transformation tool should be flexible so you can transform data to meet a variety of analytical and operational needs.
Ideally, we would like a SQL-based data transformation tool that could be utilized by non-developers to create data models based on the warehouse and put that data into action more quickly.
Finally, we would like a tool that maintains a history of our data transformations. Documentation about existing data models and how these models relate to each other can provide better context for how data has been manipulated over time.
When considering these requirements for a transformation tool, one option stood out because it encompassed all features we wanted and was free and open-source. That tool was DBT, or Data Build Tool. We opted to go with the cloud version of DBT because of its ease of use and simple to understand UI.
Data Transformation: How We Use DBT
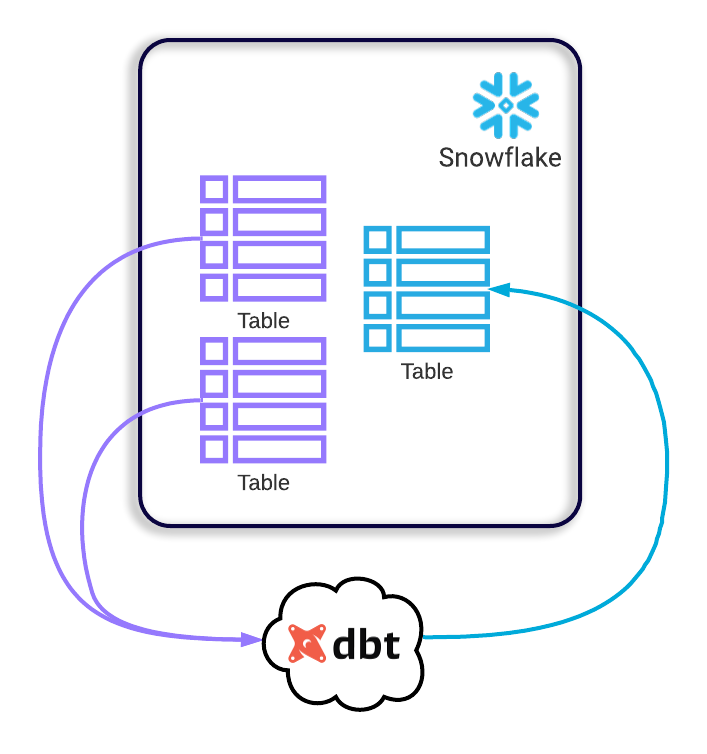
In particular, Tapestry uses DBT to aggregate data and handle duplicate entries. Other transformations you might want to perform include changing column names or copying only the particular fields you need from one table into a new table.
Because DBT has its own cloud version, Tapestry doesn’t need to provision any resources for it.
4.3 Data Syncing
The syncing phase is where we send data back into external tools that can then act on the data.
Much like data ingestion, this requires a library of API connectors, specific to each destination, and the ability to schedule when you want to transfer your data. However, data syncing is more challenging than ingestion in that the data must conform to the destination’s schema.
This concept of syncing data back into your tools is relatively new and has recently been coined reverse ETL. If you recall, ETL and ELT are concerned with moving data from your tools into your warehouse, and reverse ETL moves data out of your warehouse and into your business’s operational tools. This term, however, while becoming quite common, does not describe the process well, which is why we prefer the term “data syncing.”
Data Syncing Tool: Grouparoo

While proprietary tools exist in the data syncing space, like Census and Hightouch, we opted to find one that was open-source.
We ultimately went with Grouparoo. It allows us to schedule data syncing into external tools and validate that the data conforms to the destination schema.
Data Syncing: How we Deploy Grouparoo
Grouparoo recommends deploying their web application stack with an application layer and a data layer.
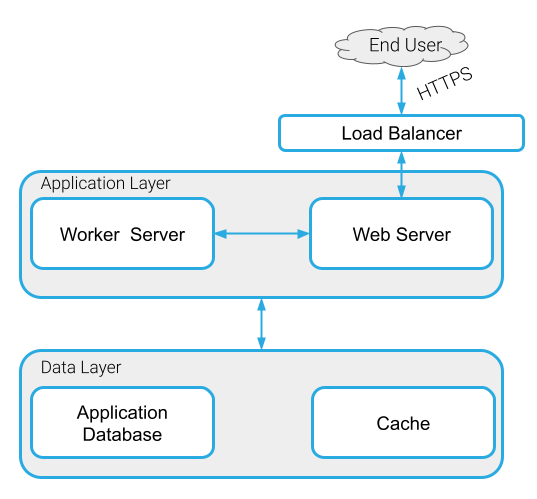
The application layer is where a worker server and web server will reside. When a request to sync data up with external sources comes in, it first hits a load balancer which directs the request to the web server. From there, the web server can then off-load the task to the worker server if the task will take a long time to complete. When these slower jobs are run in the background, it improves the responsiveness of the web server.
The data layer houses the application database as well as the cache. Grouparoo recommends using Redis to serve as both the cache and also as the background-job queue for the worker server. They also suggest using Postgres as the database where your user data will be stored.
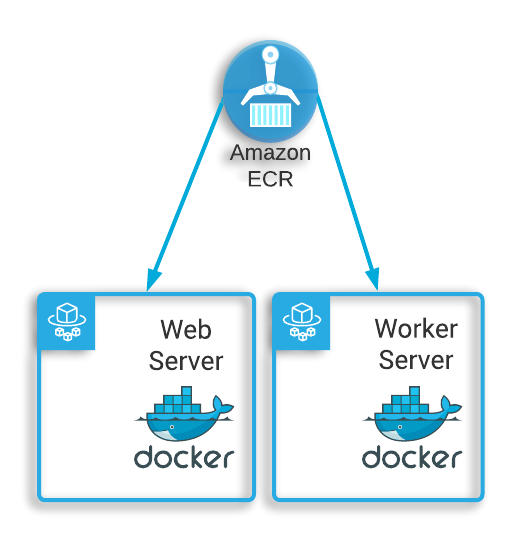
This architecture informed how Tapestry chose to deploy Grouparoo to the cloud. Given the distributed nature of this architecture, we thought it was appropriate to deploy each component as its own Docker container.
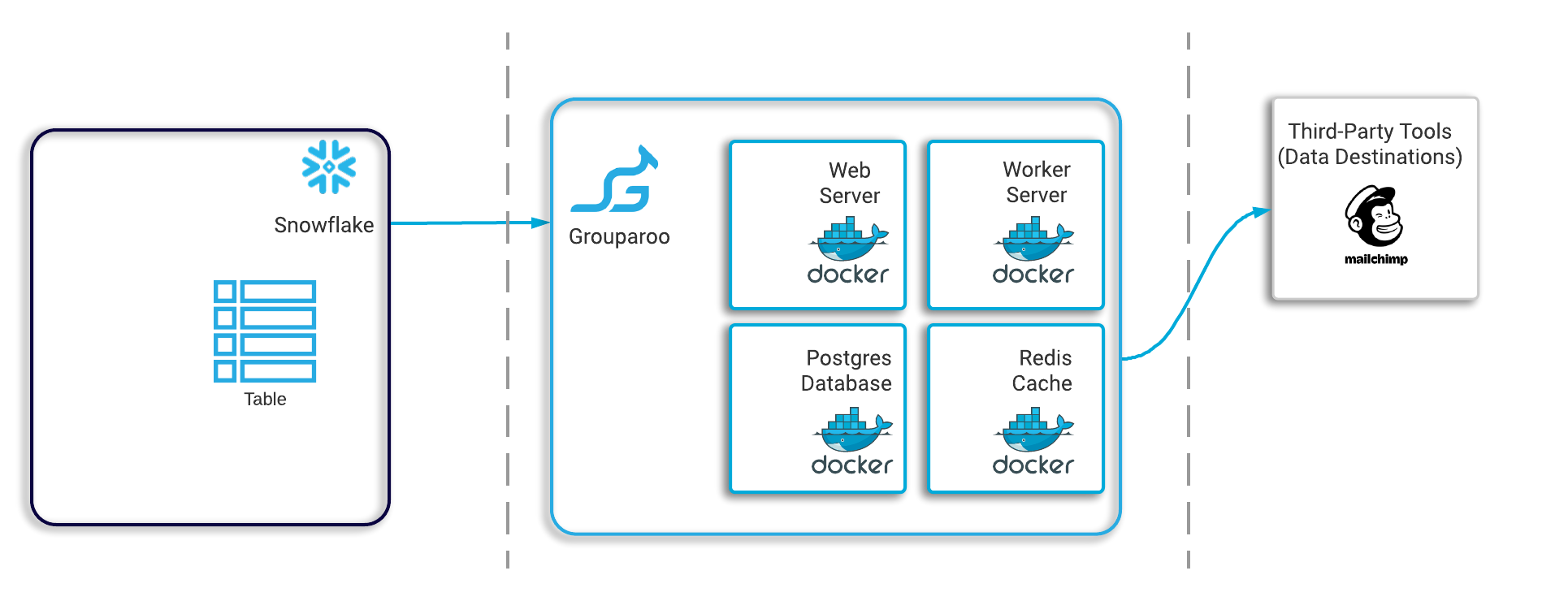
This way each container would have only one concern, and the decoupling of responsibilities would make it easier to horizontally scale in the future. First, Tapestry provides a generic Redis and Postgres Docker image to run the containers for the data layer. Then, Grouparoo provides a Docker image that can be used for deploying the web and worker service. Starting with their base image, we add the necessary configuration to integrate Snowflake as the data warehouse for Grouparoo to use as its primary data source.
Of note, Grouparoo uses Javascript or JSON files to store configuration details. Because of this, any configuration changes require the Grouparoo Docker image to be rebuilt. So we chose to push the image we provide to a repository on AWS’s Elastic Container Registry, giving the user easy and private access for any future updates.
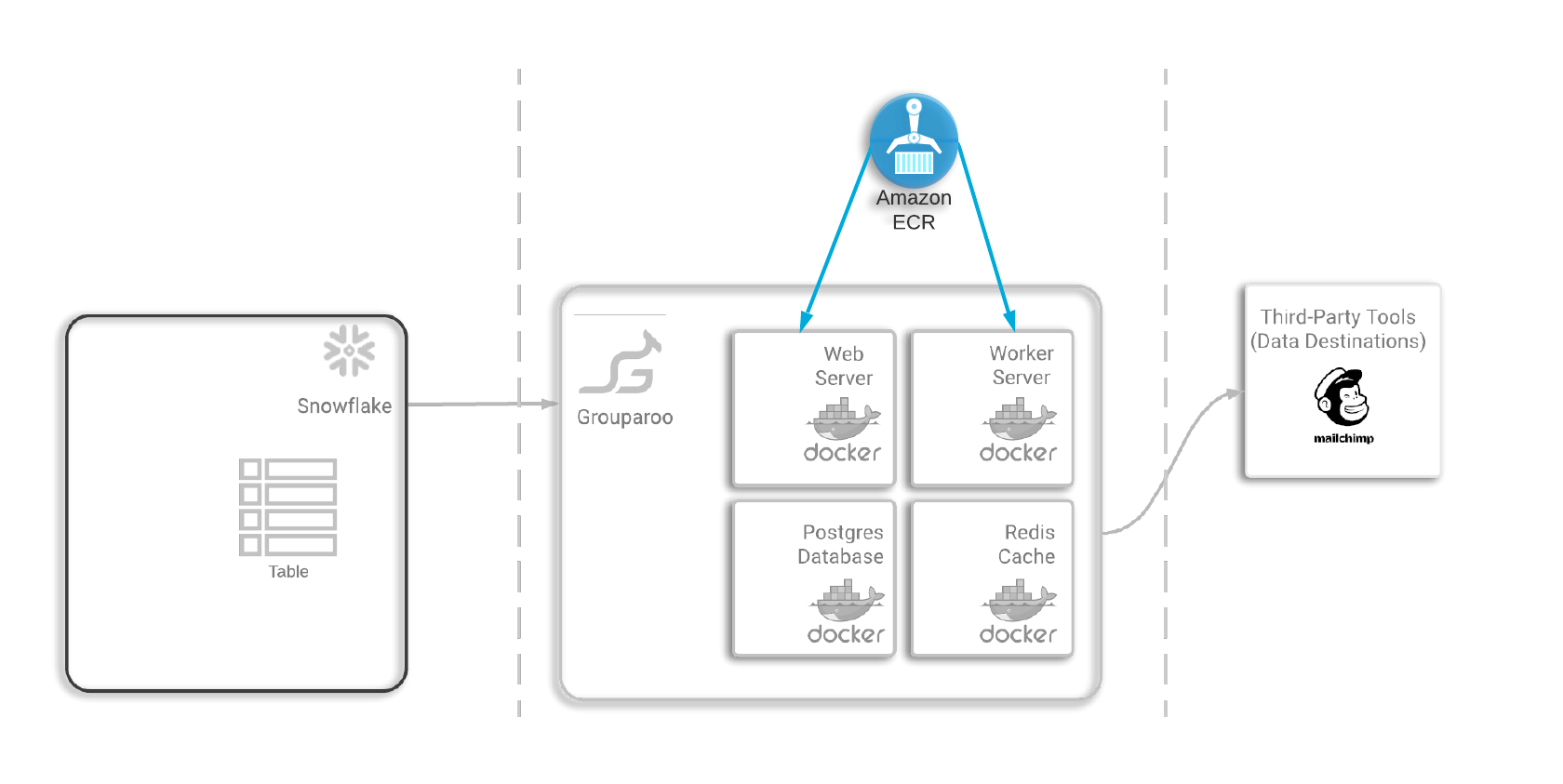
Because this is a multi-container deployment, Tapestry had to consider how best to handle container orchestration. Some popular options for container orchestration include Kubernetes, Docker Swarm, and Amazon Elastic Container Service, or ECS. Kubernetes and Docker Swarm are both highly configurable; however, the learning curve is steep. So we decided to use ECS to handle container orchestration for Tapestry’s Grouparoo deployment because it manages and scales containers efficiently and automatically. This choice also gave us the ability to use the recently rolled-out ECS and Docker Compose integration, which simplified this process even more.
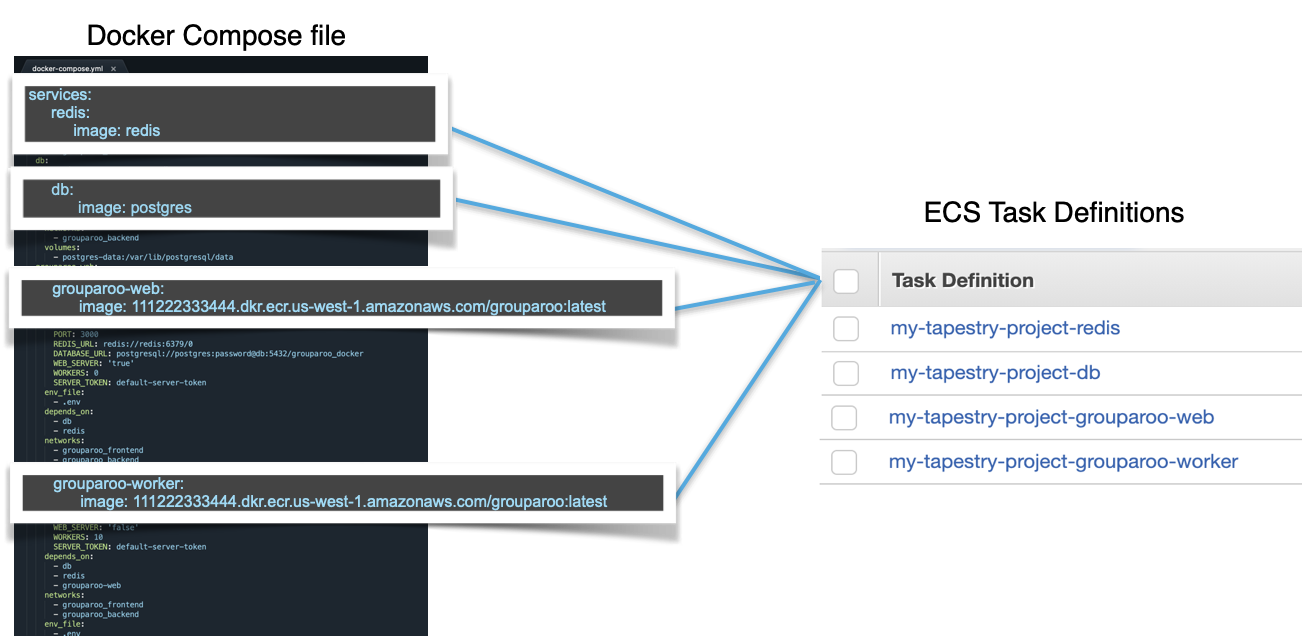
Docker Compose is a tool that allows developers to define and run multi-container applications via a YAML file. With this integration, we could seamlessly use this same docker-compose file to deploy the Grouparoo application and all its dependencies as an ECS cluster. AWS resources are created automatically based on the specifications in this file. This works because there are built-in mappings between the Docker containers defined in the file and ECS tasks.
ECS not only manages these containers, but the servers they live on as well. This occurs via AWS Fargate, a service that abstracts away server provisioning and handles it entirely on the user’s behalf. We also placed a load balancer in front of the ECS cluster for all of the same security reasons we placed one in front of our ingestion tool. Additionally, since we use a load balancer, we are also set up nicely to horizontally scale in the future if needed.
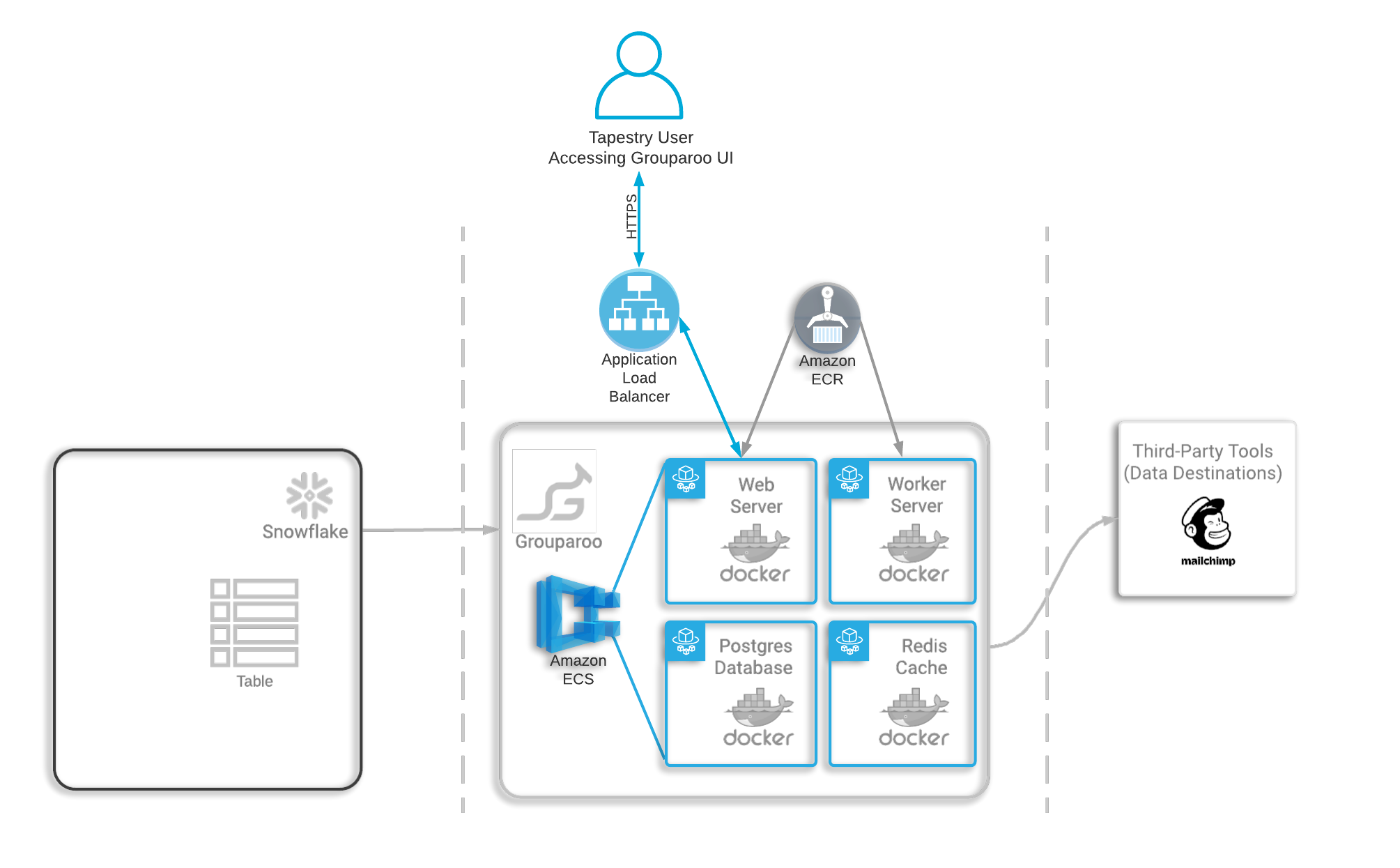
Once Grouparoo is deployed, you are ready to start pulling data from your warehouse, and syncing it into other third party tools, like Mailchimp.
5 Using Tapestry
5.1 Prerequisites & Installing Tapestry
Getting started with Tapestry is pretty simple. You will need the following:
- Node and NPM
- An AWS account and AWS CLI
- Docker
If you were the developer, you would first need Node and NPM installed since Tapestry is a Node package. Since Tapestry provisions several AWS resources, you are required to have an AWS account and the AWS Command Line Interface configured on your machine. Finally, you will need to have a Docker account and have it installed on your machine.
After these preliminary steps, all you would need to do to get started is run npm i -g tapestry-pipeline, and a host of commands will be provided to you.
5.2 Tapestry Commands

As a new user, the first Tapestry command you would run is tapestry init.
With tapestry init, you give your project a name, and Tapestry will provision a
project folder along with an AWS CloudFormation template. This template allows you to provision and configure
AWS resources with code. In particular, this template is used to provision resources for the data ingestion
phase of the pipeline. What Tapestry provides for the syncing phase of your pipeline is dependent upon which
command you run next.
5.3 Deploy vs. Kickstart Commands
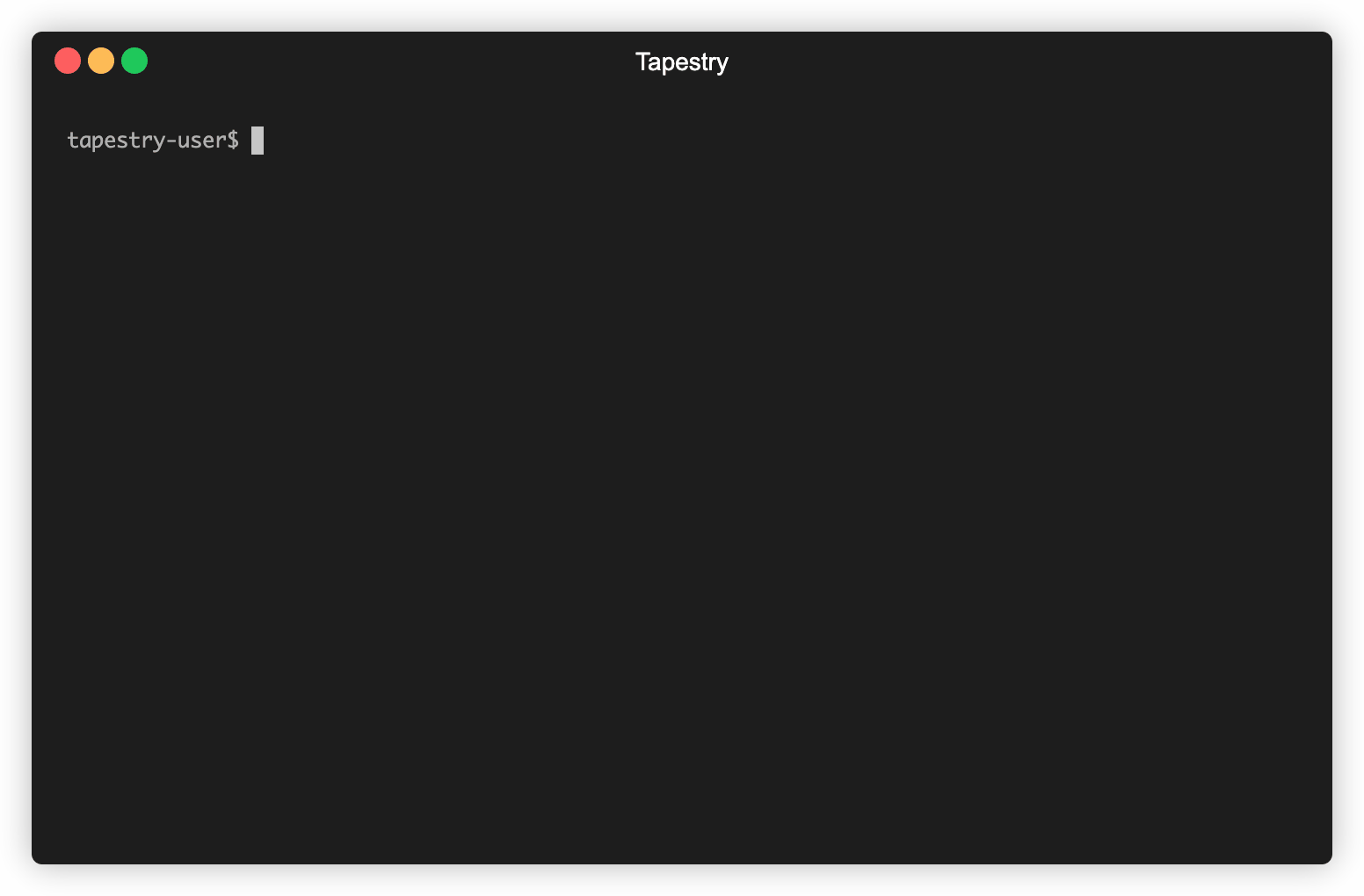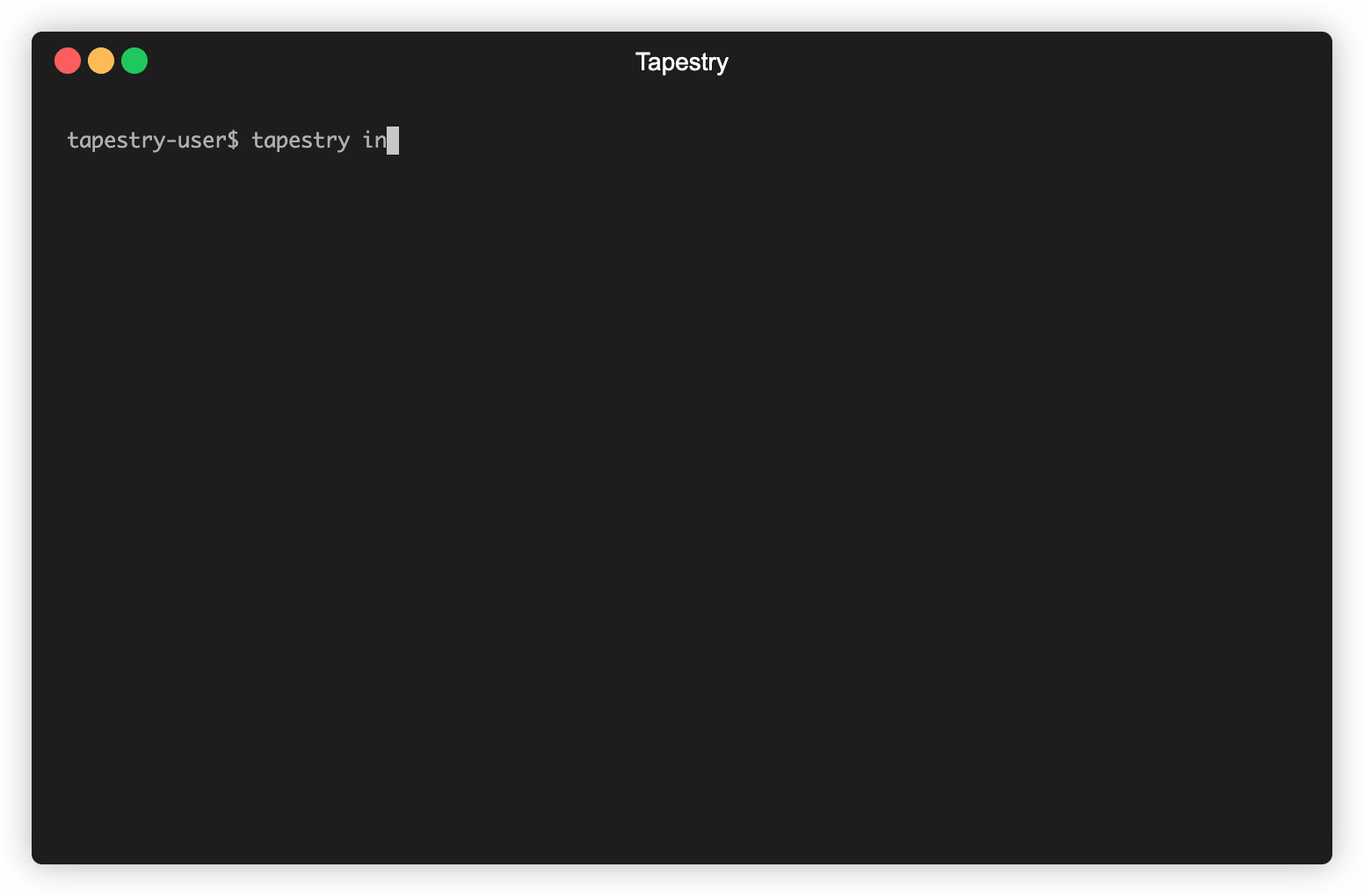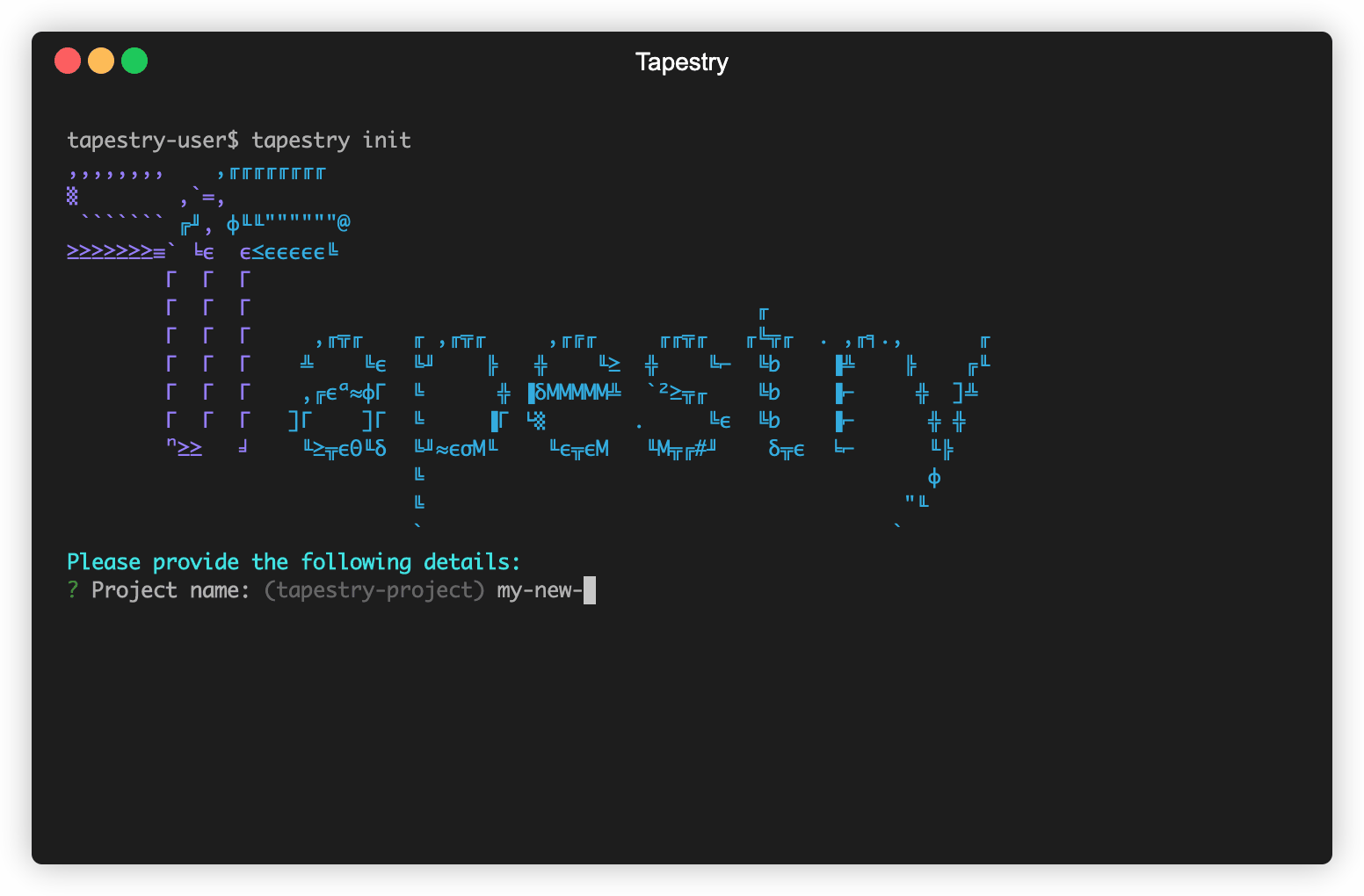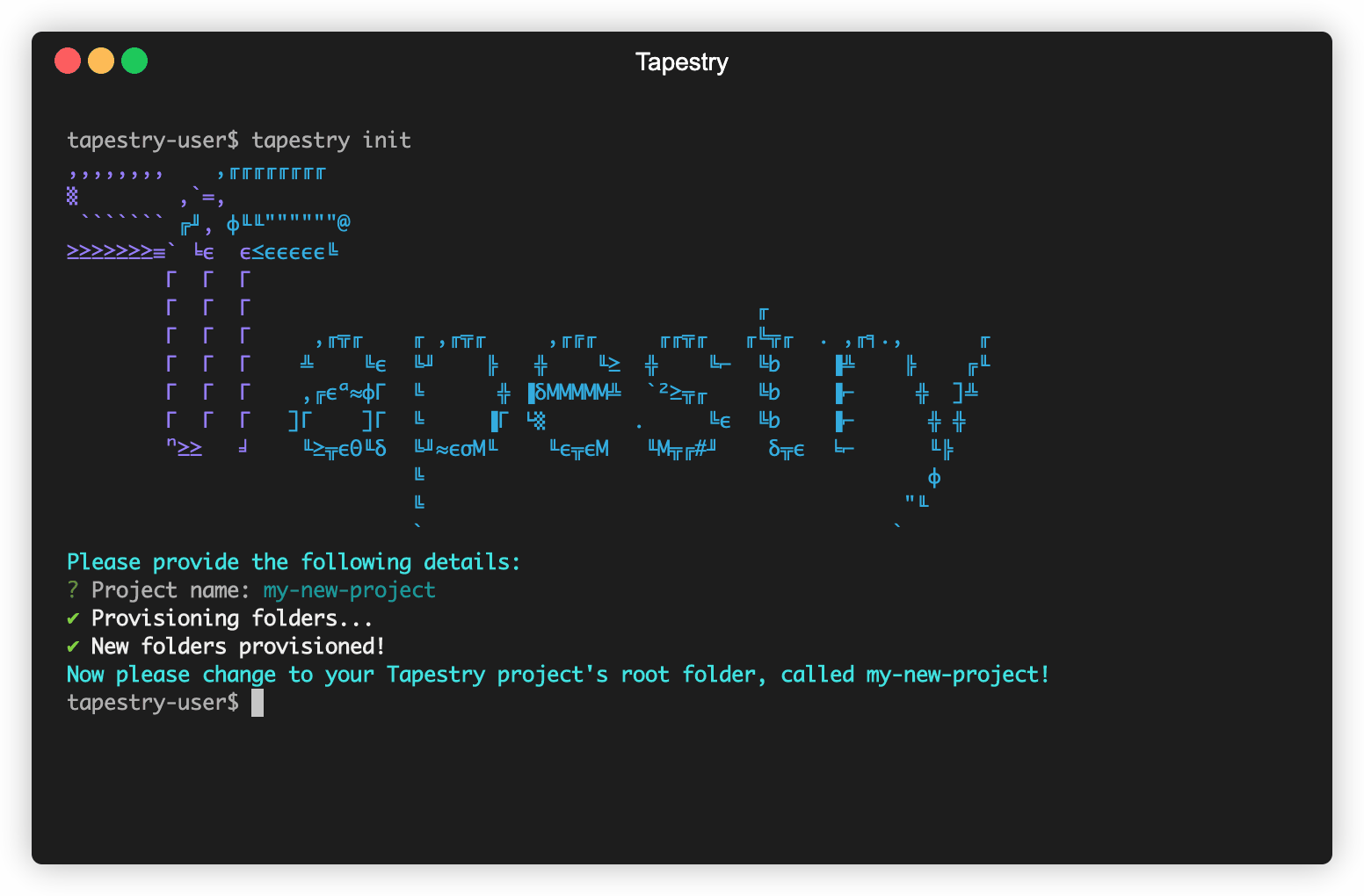
Next, you have a choice between the tapestry deploy or tapestry kickstart commands. Once you make your selection, Tapestry provides all the
necessary configuration files for the data syncing phase.
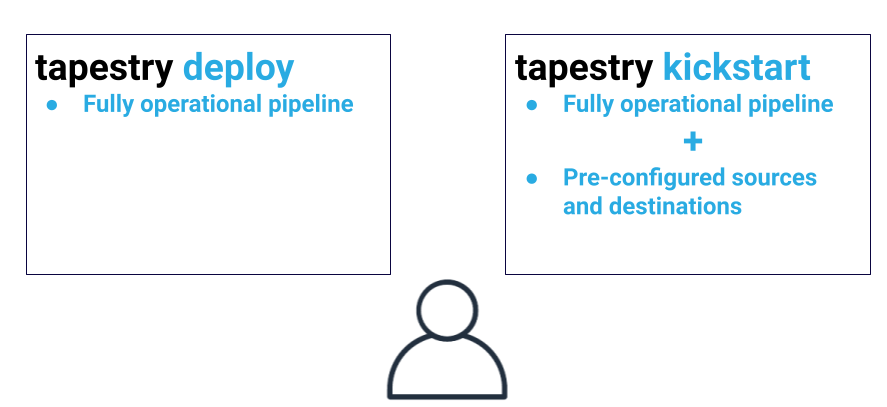
Both commands automate the deployment of a fully operational pipeline, but kickstart includes two pre-configured sources, Zoom and Salesforce, along with one
destination, Mailchimp. These pre-configured third-party tools set up your pipeline to have immediate
end-to-end data flow, beginning with data ingestion and ending with data syncing into these tools. Regardless
of which command you choose, note that a Snowflake account is required for both deploy and kickstart.
5.4 End-to-End Demo
To better show the full flow of data through a Tapestry pipeline, this section will walk through our tapestry kickstart command.

Prior to execution, you will have to own or create accounts with Zoom, Salesforce, and Mailchimp. kickstart then begins by prompting you with a short series of questions about the
previously mentioned accounts, as well as Snowflake, Tapestry’s data warehouse of choice. Tapestry stores this
information in the AWS SSM Parameter store. This keeps sensitive data safe, but also accessible.
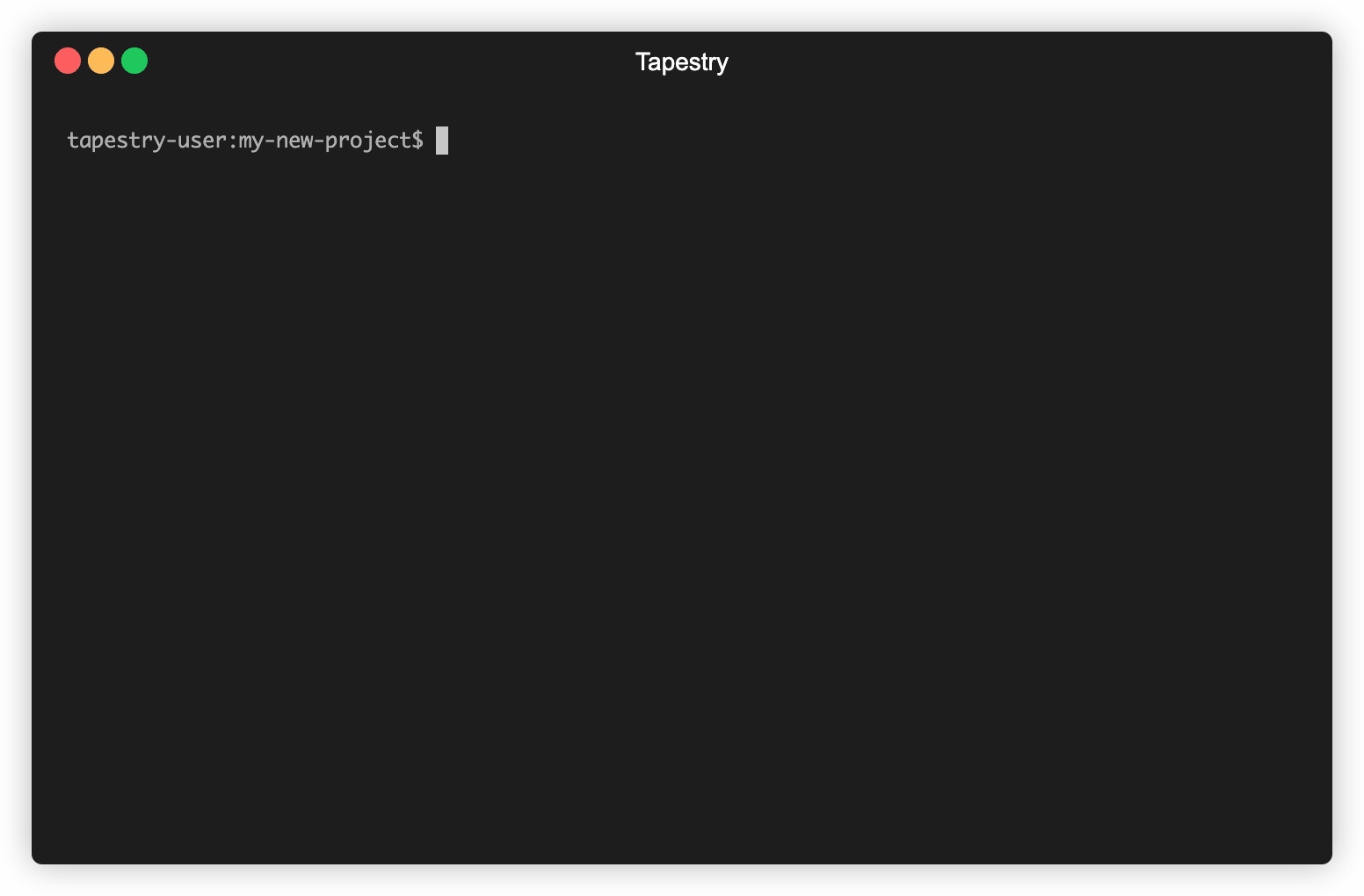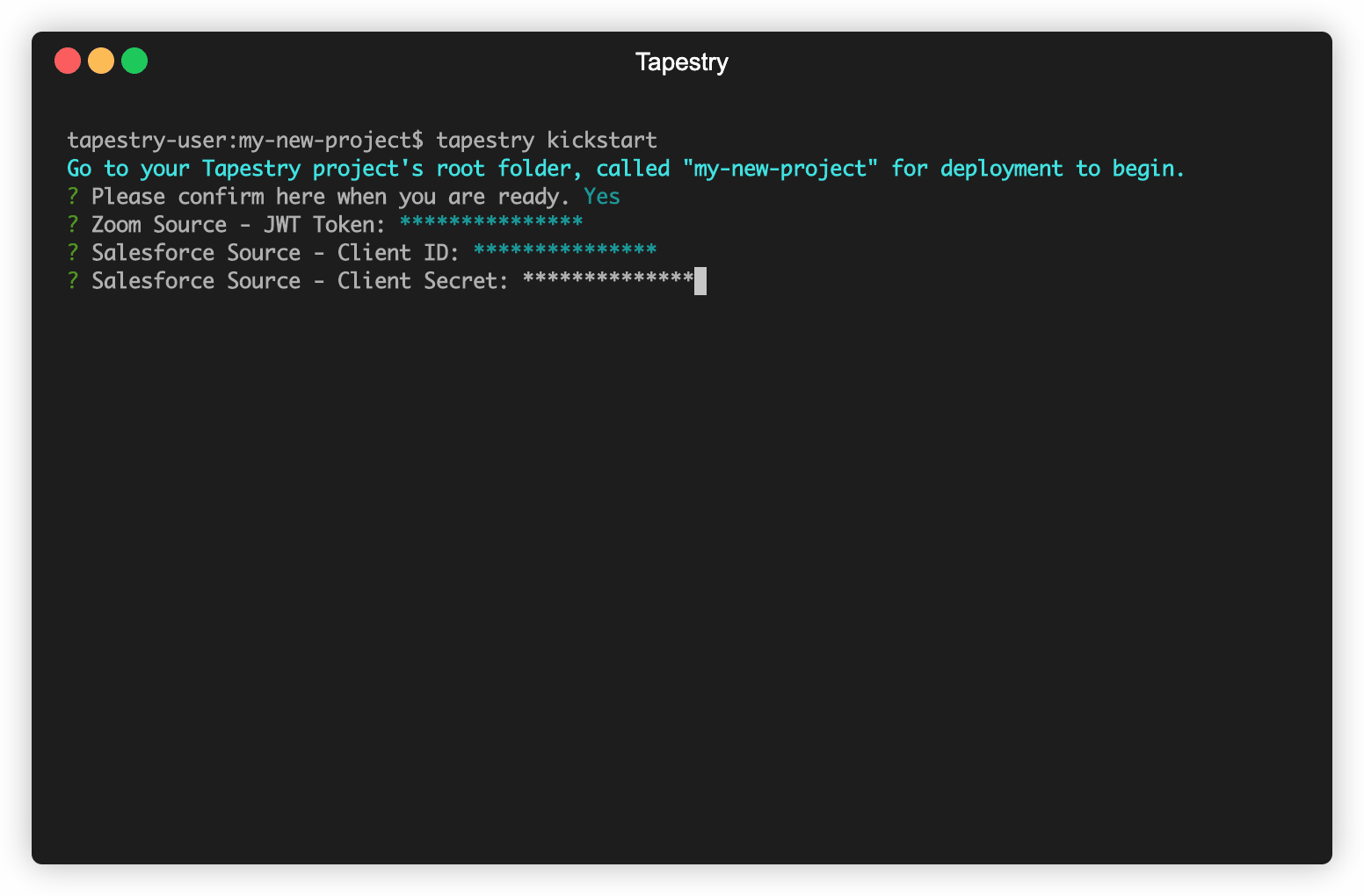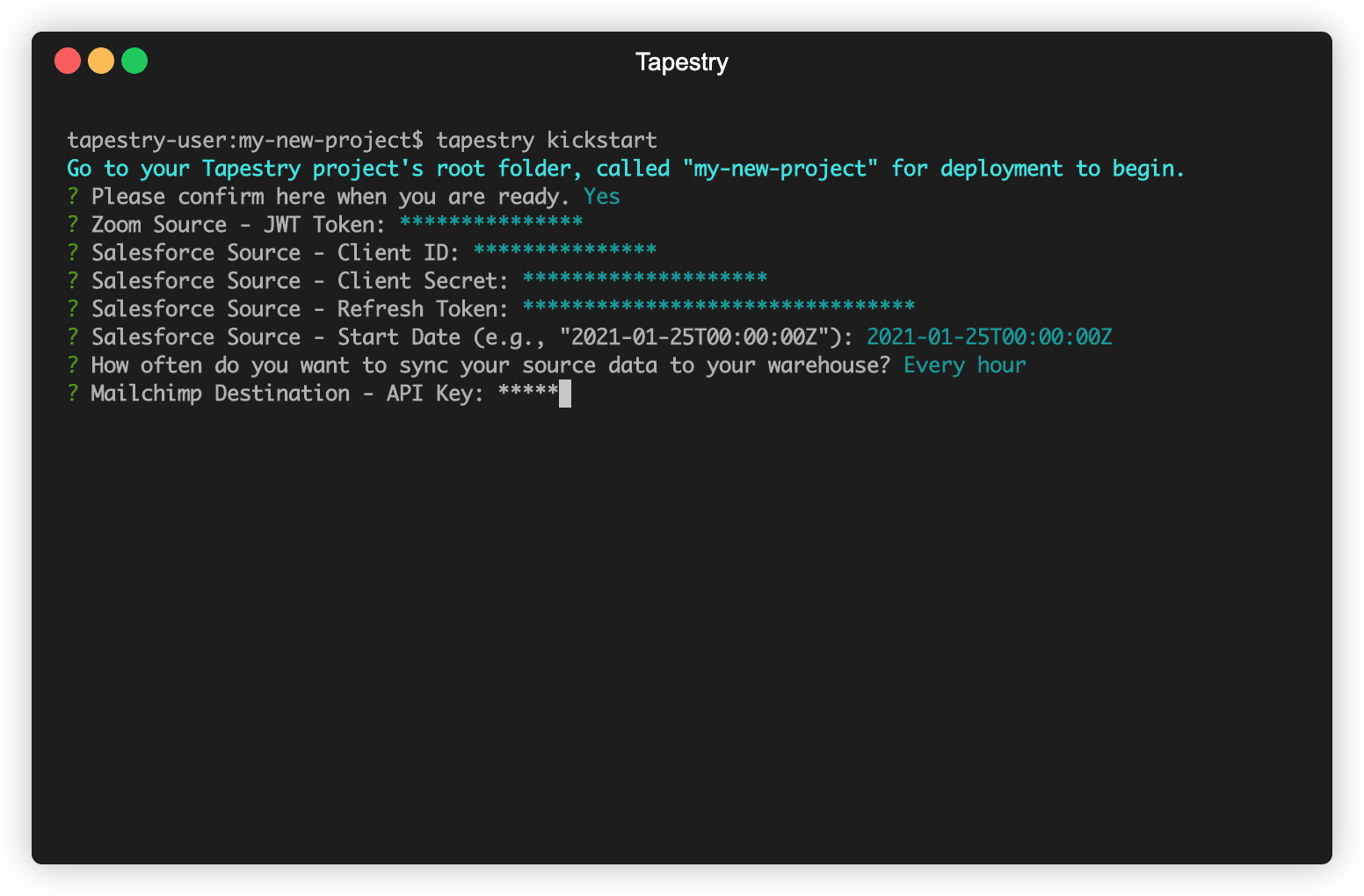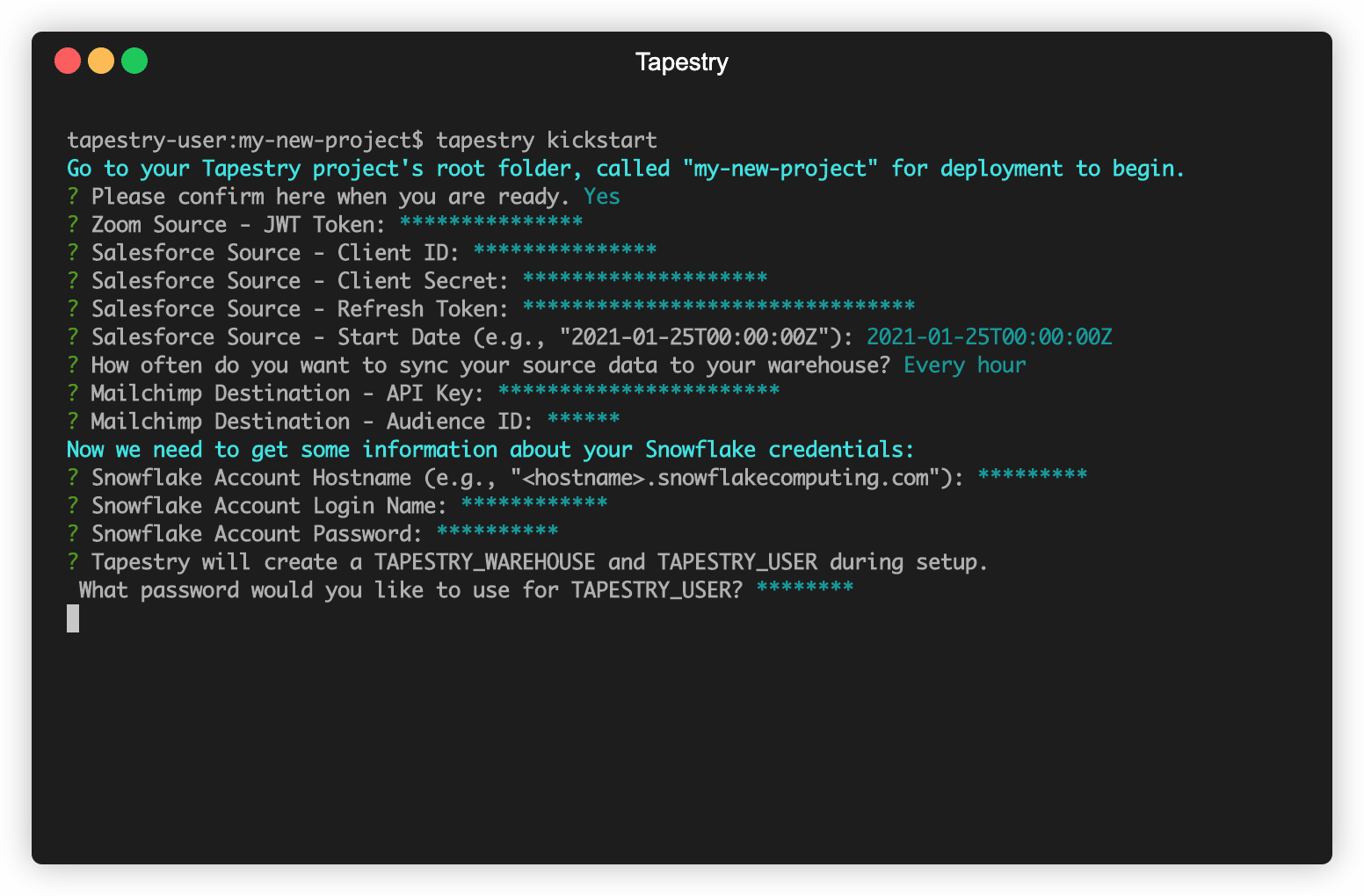
After your information has been collected, kickstart continues by creating the
necessary databases and tables within your data warehouse to be utilized by both your ingestion and syncing
tools.
Let’s quickly review the infrastructure that this command is provisioning.
Tapestry uses the CloudFormation template supplied during the init command to
create a CloudFormation stack, provisioning AWS resources specifically related to your ingestion tool,
Airbyte. These resources include an S3 staging bucket, an EC2 instance for Airbyte to run on, and an
Application Load Balancer to route traffic to our EC2 instance. Airbyte is then configured to extract certain
data from your Zoom and Salesforce accounts and send it over to your warehouse.
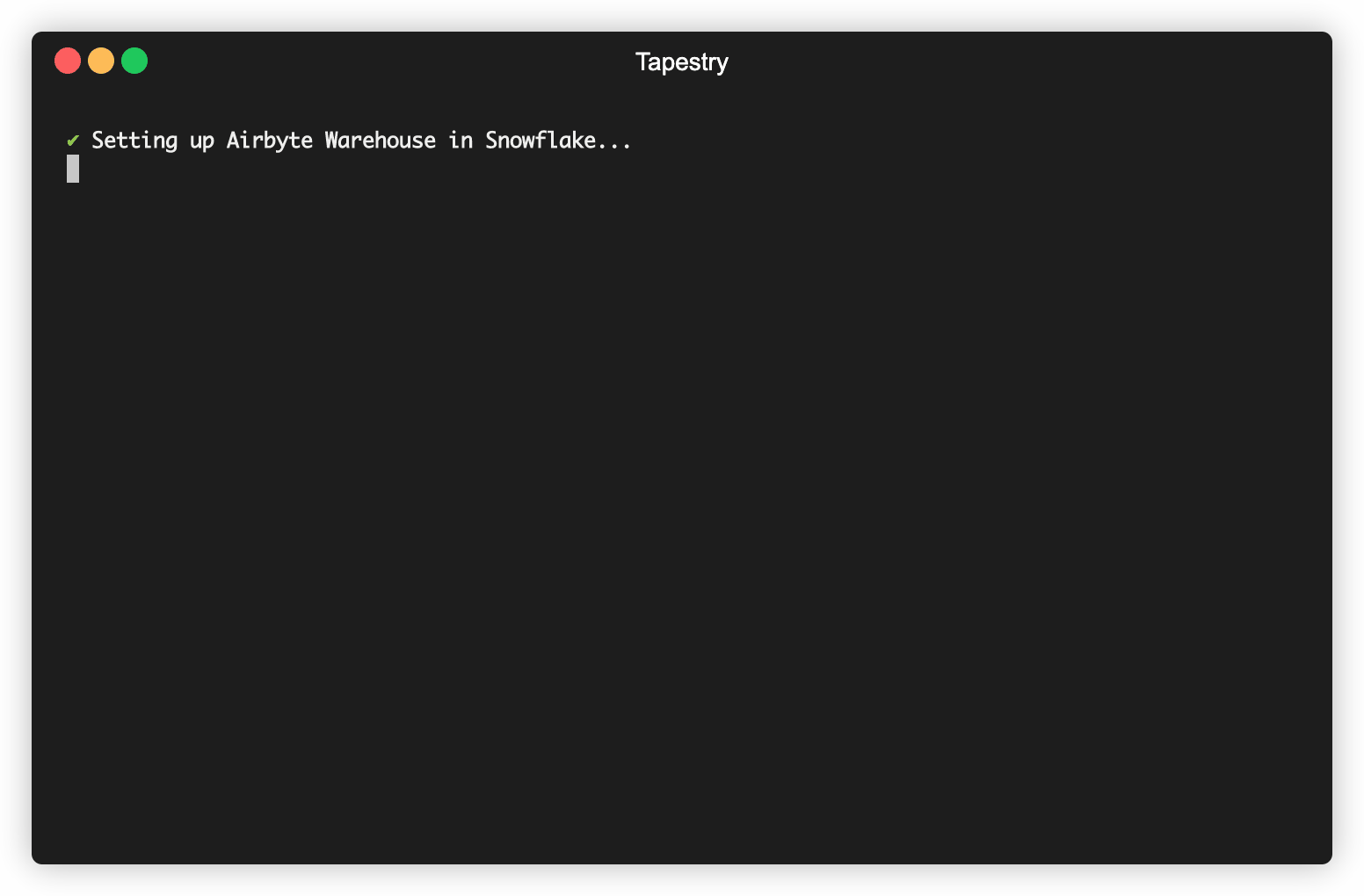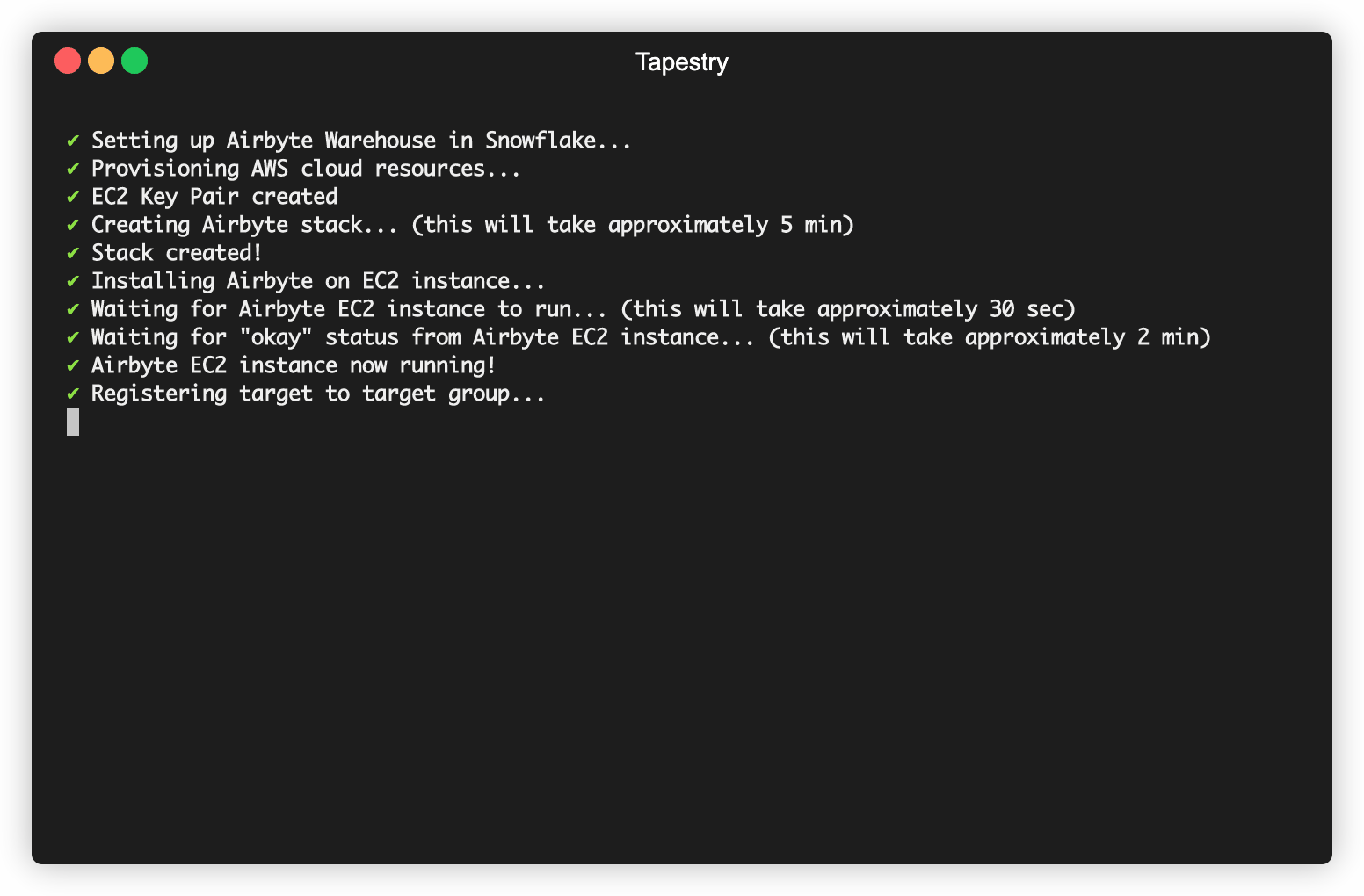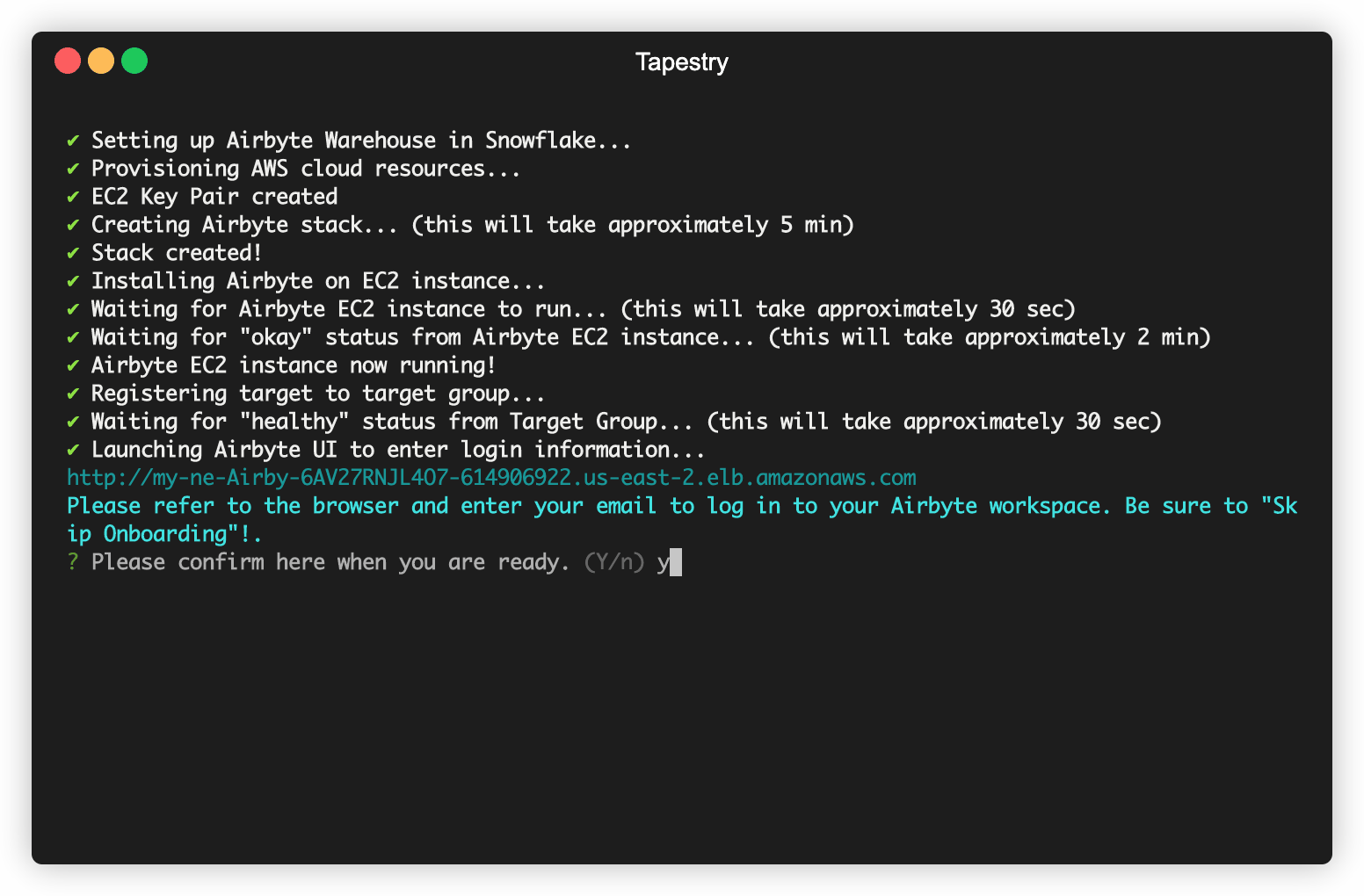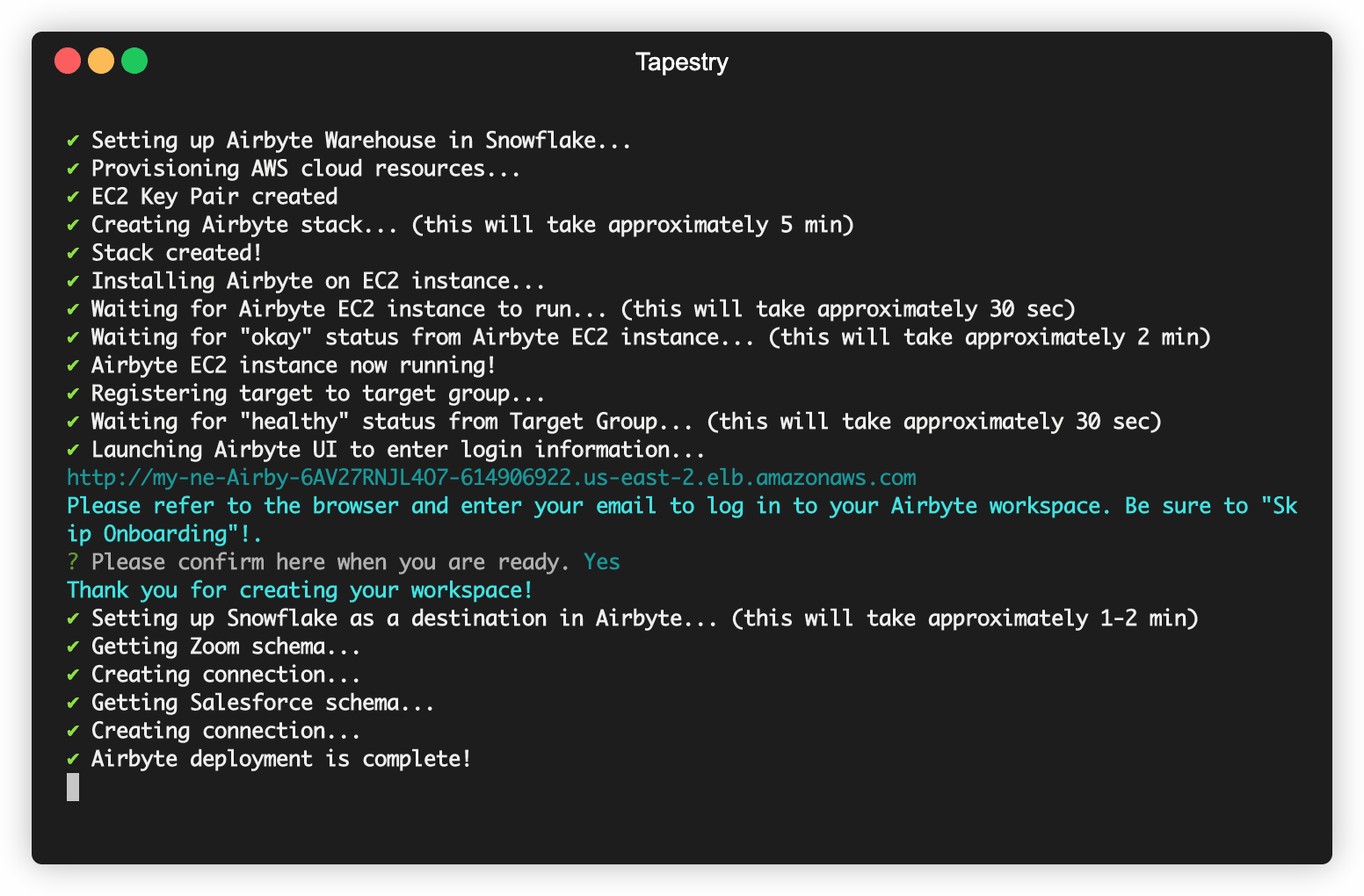
You will then be asked to carry out a few steps so the data is transformed in your warehouse using the data model Tapestry provides for DBT. The raw data will be aggregated from both sources into one transformed table, filtered for duplicates, and appropriately formatted to be synced to Mailchimp.
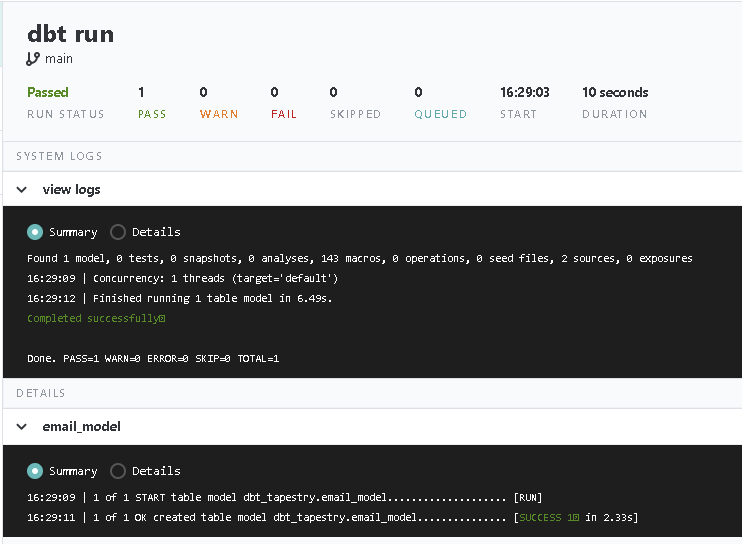
To complete the pipeline, kickstart creates another CloudFormation stack, this
time spinning up various AWS resources for your syncing tool, Grouparoo.
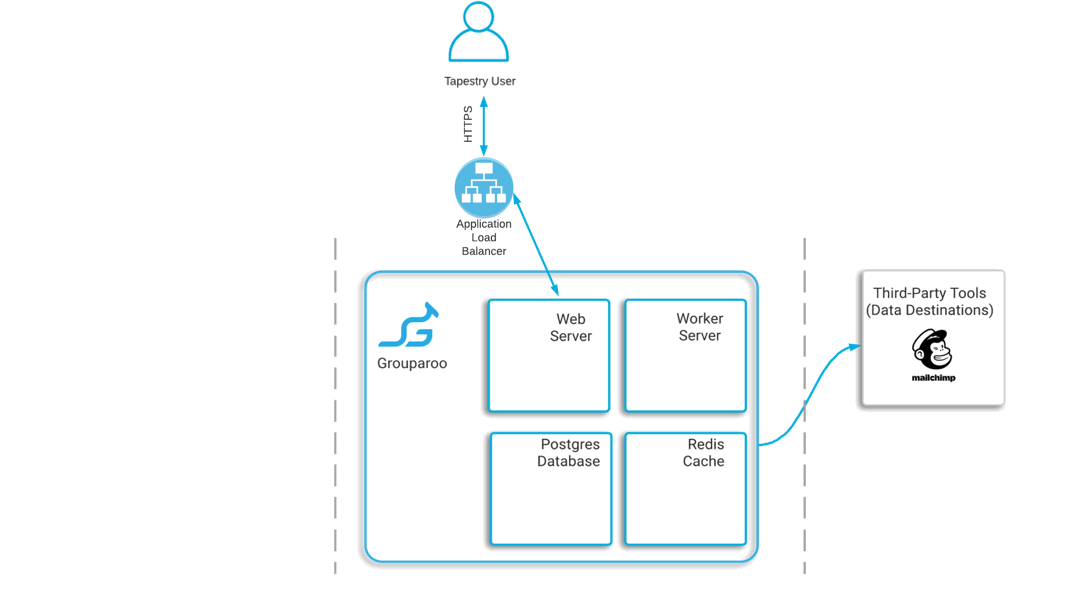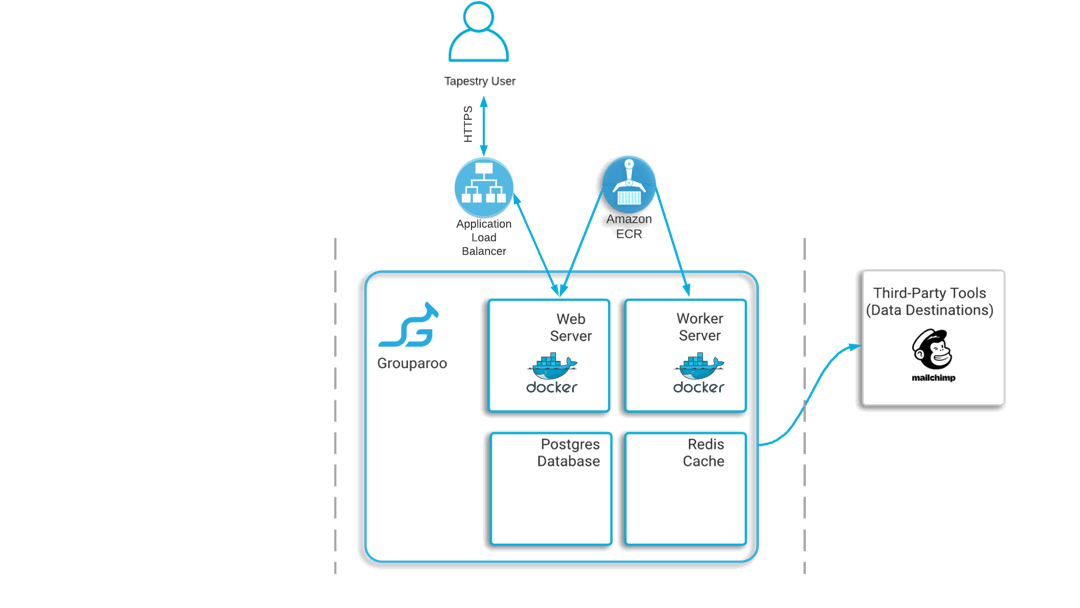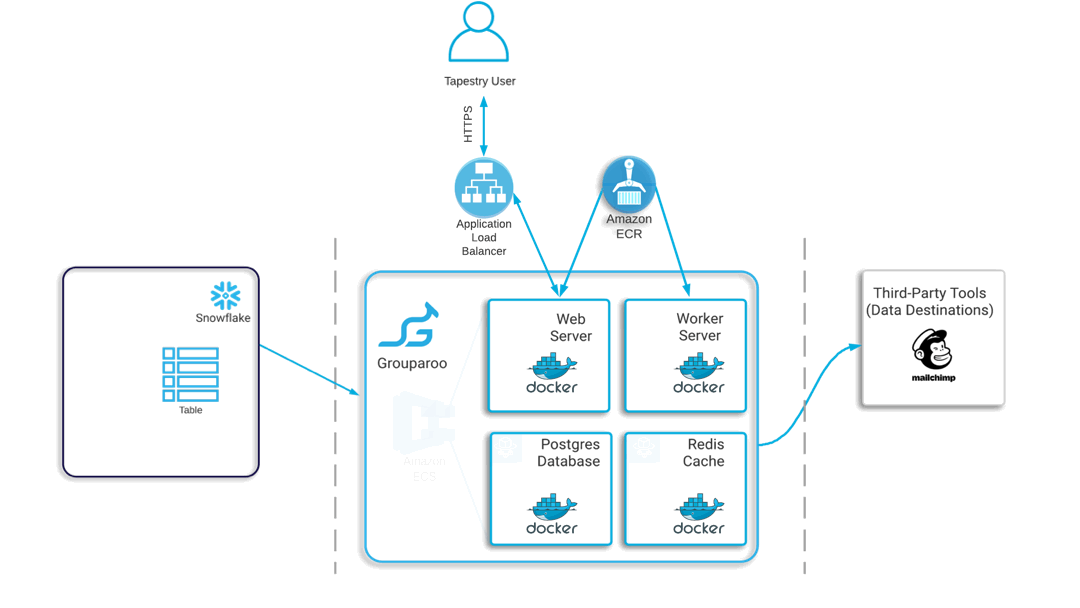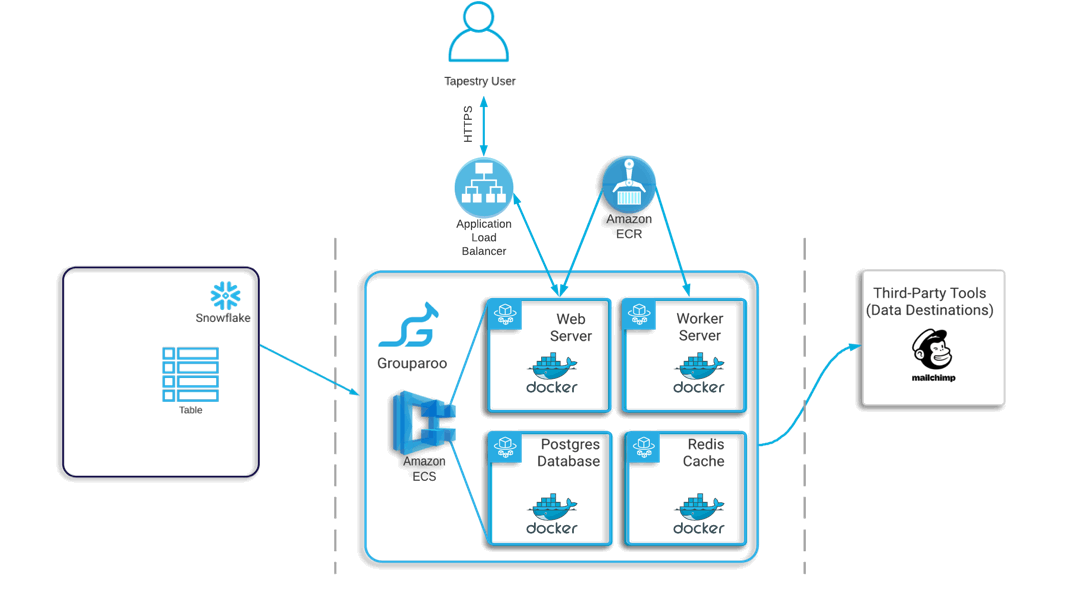
These resources include an Elastic Container Services cluster to run your Grouparoo application, an Elastic Container Registry repository with your Grouparoo Docker image stored, and another Application Load Balancer to route network traffic to your cluster.
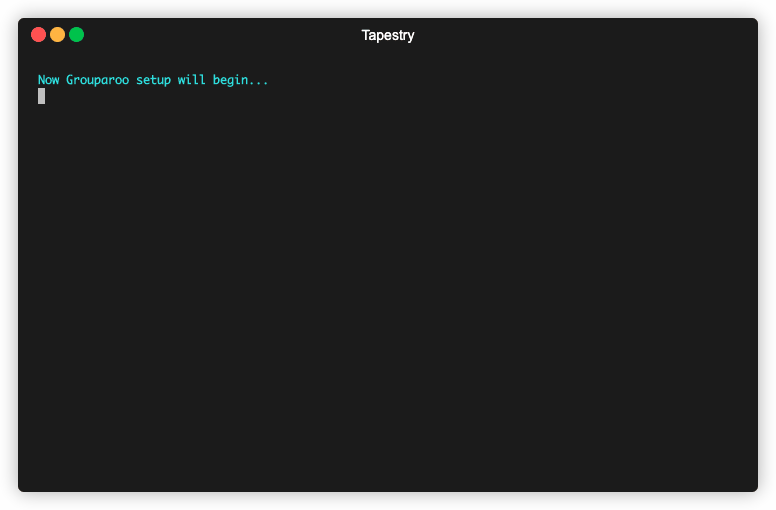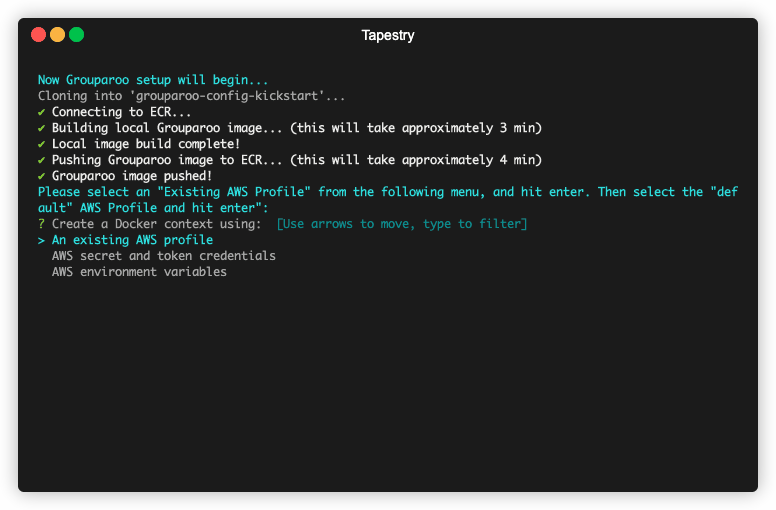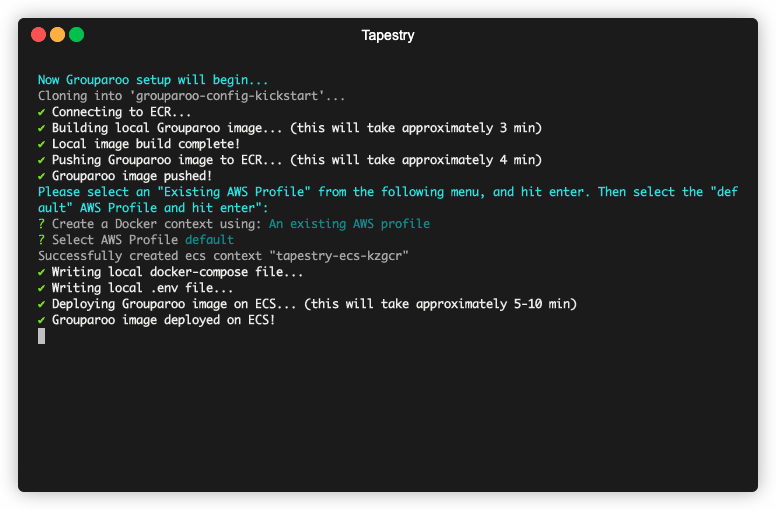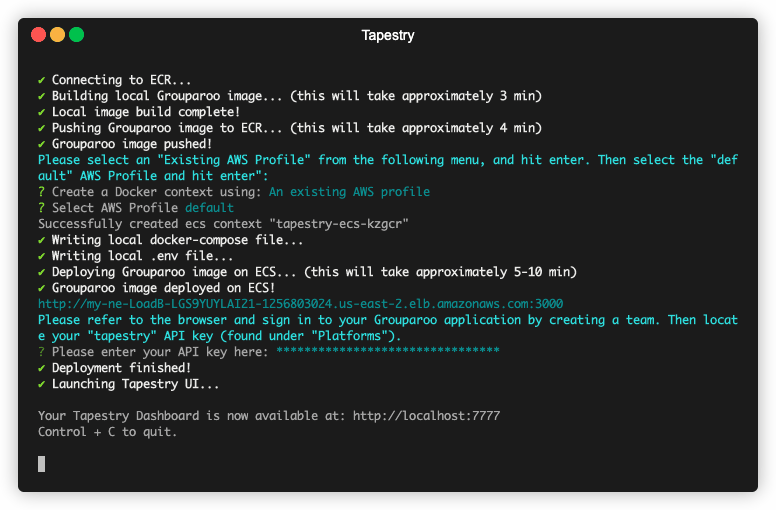
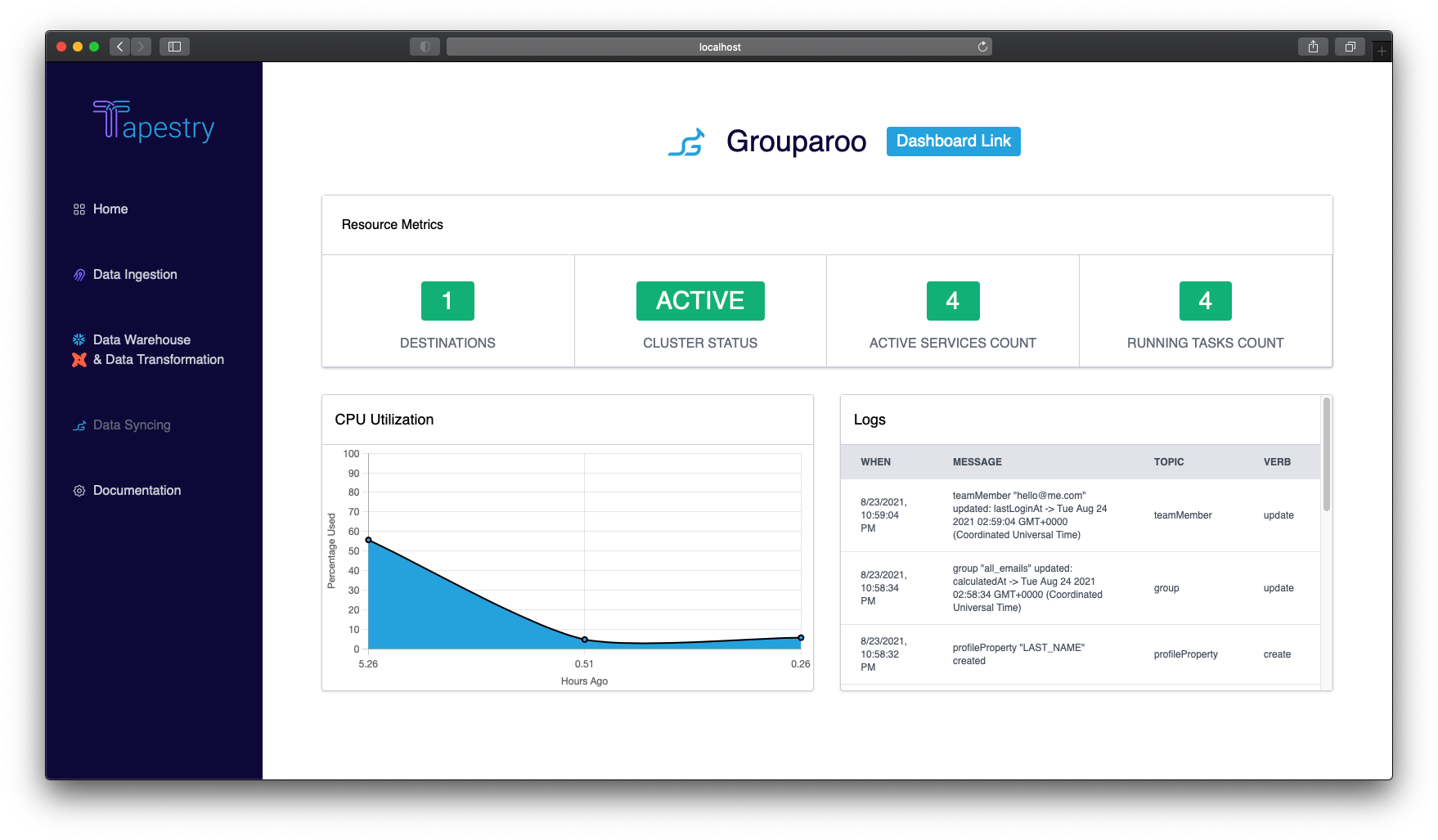
5.5 Tapestry Dashboard
If you are deploying a new pipeline, Tapestry automatically launches your very own local Tapestry Dashboard.
Additionally, anytime you'd like to view the dashboard, you can run the command tapestry start-server to spin up and launch the UI at http://localhost:7777.
The dashboard contains documentation for how to use Tapestry, along with various pages for each section of your pipeline. Each page displays metrics that give you better insight into the health of each component. They also include links to the UIs for all your date pipeline tools: Airbyte, Snowflake, DBT, and Grouparoo.

Some important metrics we track on the dashboard include:
- Number of data ingestion sources currently operational
- Number of data syncing destinations currently operational
- EC2 instance status
- ECS cluster status
- CPU utilization
- List of source tables in the data warehouse
- List of transformed tables created in the data warehouse
- Logs for each tool for increased observability
5.6 Tapestry Data Flow
Now let’s actually see data flow through the entire pipeline with an example using the tapestry kickstart command.
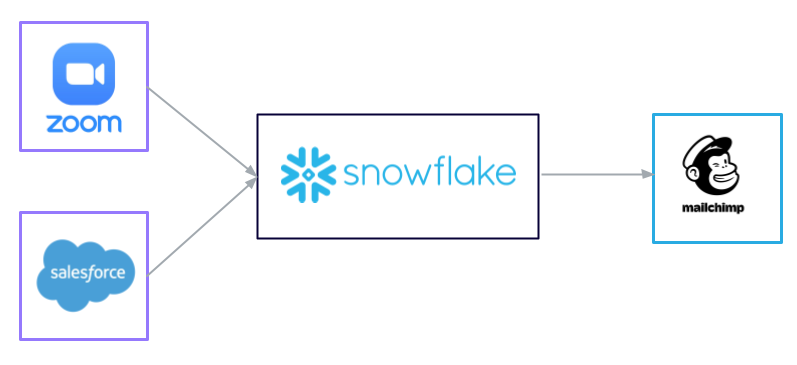
Our goal in this example is to extract data from both Zoom and Salesforce and push it to our data warehouse, Snowflake. From there, we want to combine a list of webinar registrants from Zoom and Salesforce contacts into one single table, and filter out any duplicates along the way. Finally, we want to send this complete set of data over to Mailchimp.
Zoom Data
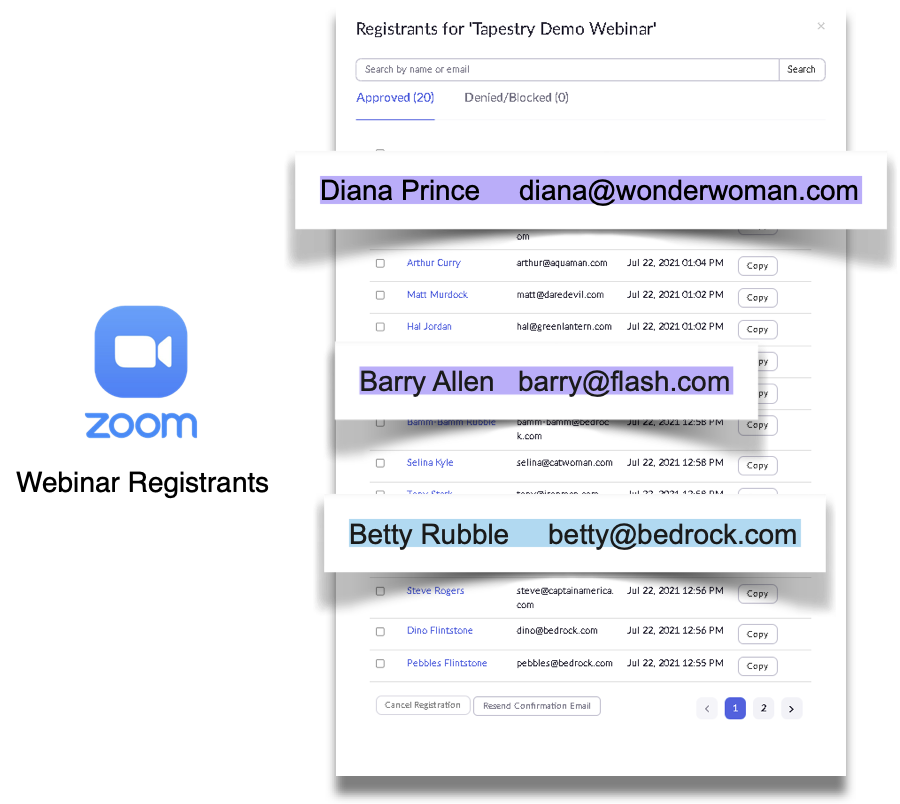
As you can see from this table, we have several different people who have registered for a Zoom webinar. Of particular note are Diana Prince, Barry Allen, and Betty Rubble. As indicated in blue, Betty Rubble is a unique contact only found in Zoom, while the purple around Diana and Barry indicates that they are contacts found in both Zoom and Salesforce. Our goal is to get all three of these entries over to Mailchimp, with only one entry each for Diana and Barry.
Salesforce Data
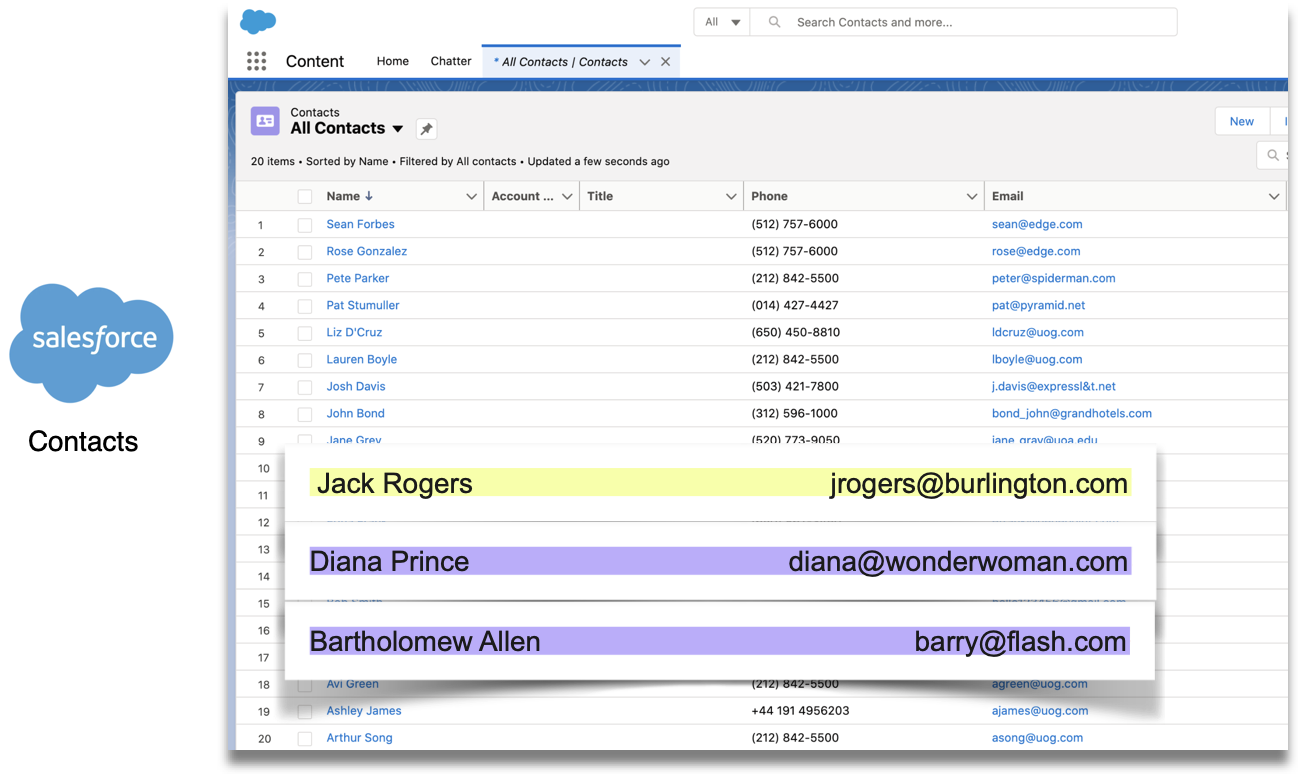
Now in Salesforce, we have a different list of customers. In yellow, there is a contact who is unique to Salesforce, Jack Rogers, while Diana and Bartholomew, a.k.a. "Barry" are in purple again, as seen in the Zoom list.
Even though Barry is going by a different first name in Salesforce, his email is the same across both sources, allowing us to uniquely identify him. This means that when we combine the two lists, we can use the email address field as a unique key to eliminate record duplication.
Snowflake Warehouse
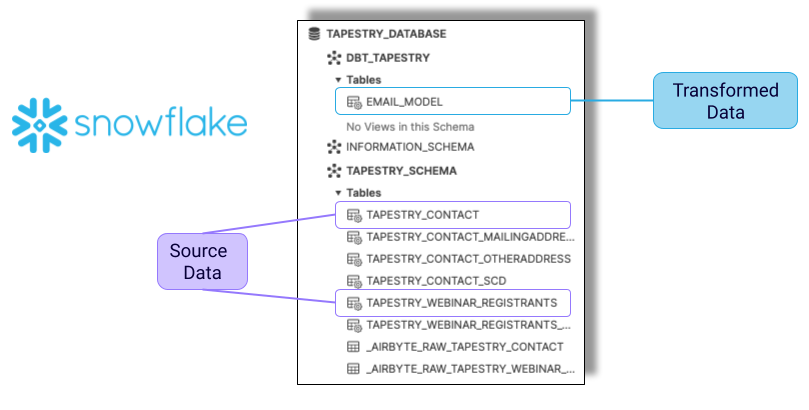
Once the data from both Zoom and Salesforce have made it into our Snowflake warehouse, we can transform the data by combining both lists, and removing duplicate entries. You can see the two tables highlighted in purple. The TAPESTRY_WEBINAR_REGISTRANTS table has all of our Zoom data, and the TAPESTRY_CONTACT table has all of our Salesforce data. The EMAIL_MODEL table that is highlighted in blue is the newly transformed table that we will sync to our Mailchimp account.
Mailchimp
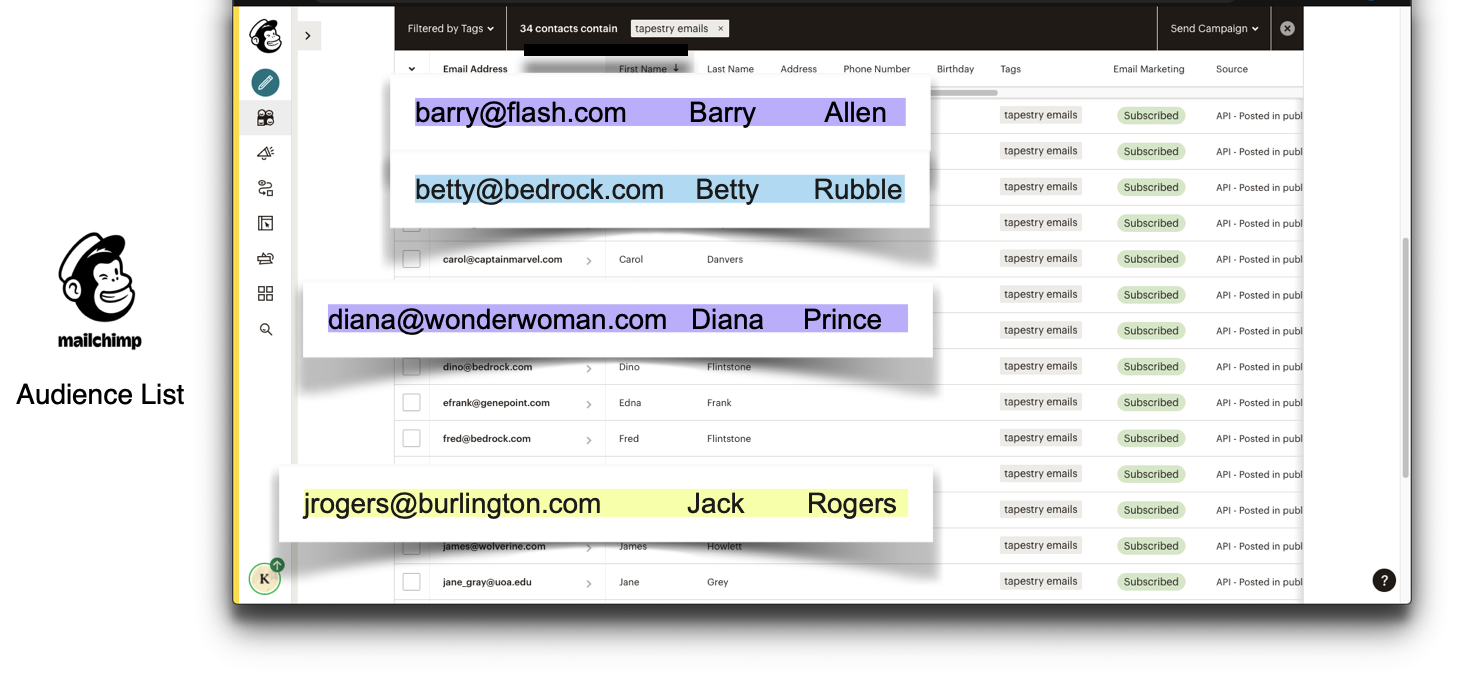
Finally, here in Mailchimp, we see that we’ve successfully synced all of our Zoom webinar registrants and Salesforce contacts, and made sure that there is only one entry for Barry and Diana. You can also see that our unique users, Betty and Jack made it over as well.
5.7 Maintenance & Management
Rebuild Command
Tapestry also supplies users with a tapestry rebuild command that is specific to
the syncing side of the pipeline. While most updates to Airbyte can be done right in their UI, Grouparoo’s
dashboard is mainly for application visibility and observability. In order to add, remove, or update any
sources or destinations, changes need to be made to the configuration files in your local Grouparoo directory.
Once these changes are finalized locally, the image must be rebuilt, pushed to a private repository in the
Elastic Container Registry, and the Grouparoo CloudFormation stack must be updated. All of these steps are
what Tapestry’s rebuild command automates. The user simply makes the changes
themselves to the configuration files and then runs tapestry rebuild. Tapestry
handles the rest.
Teardown Command
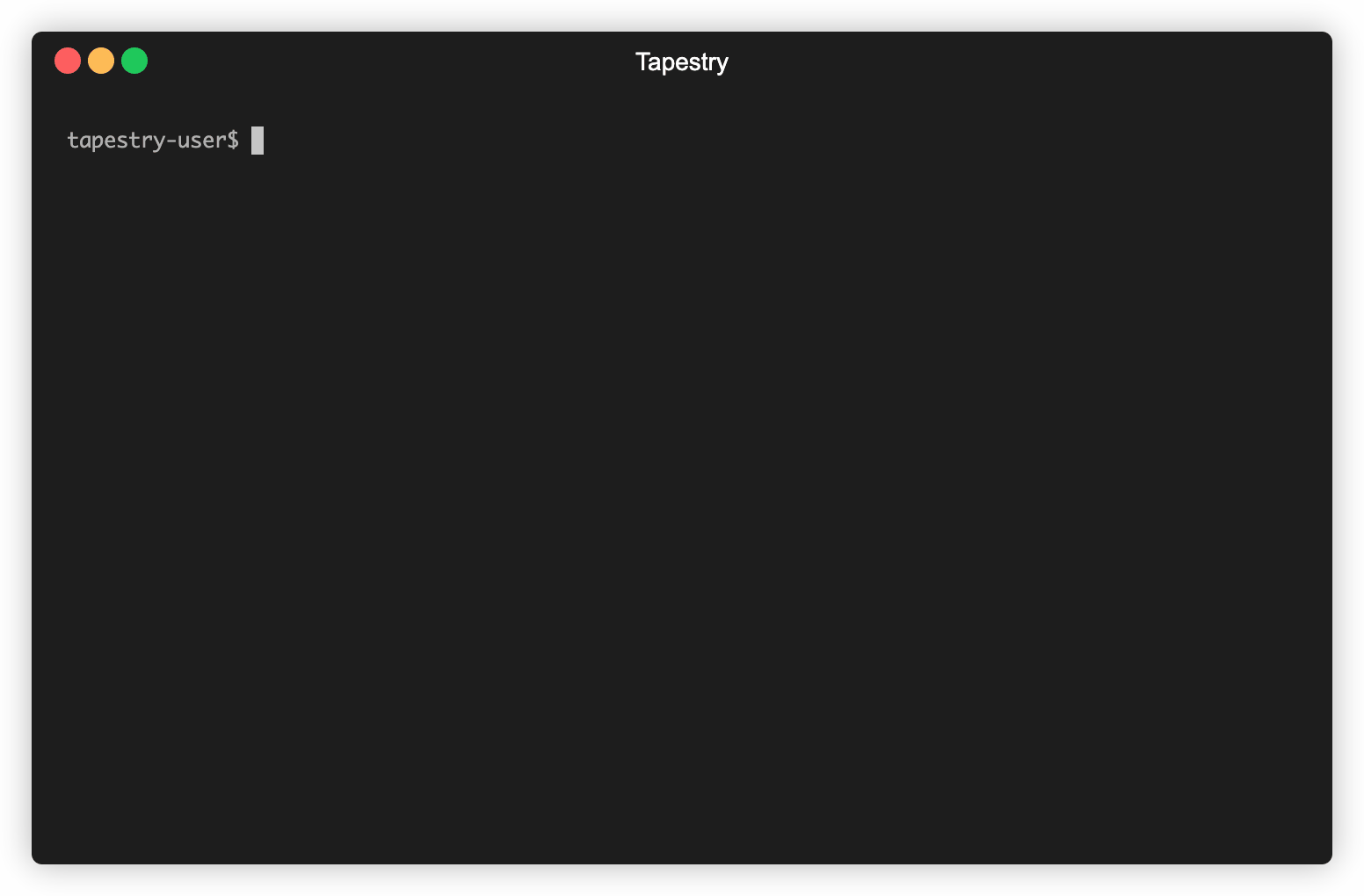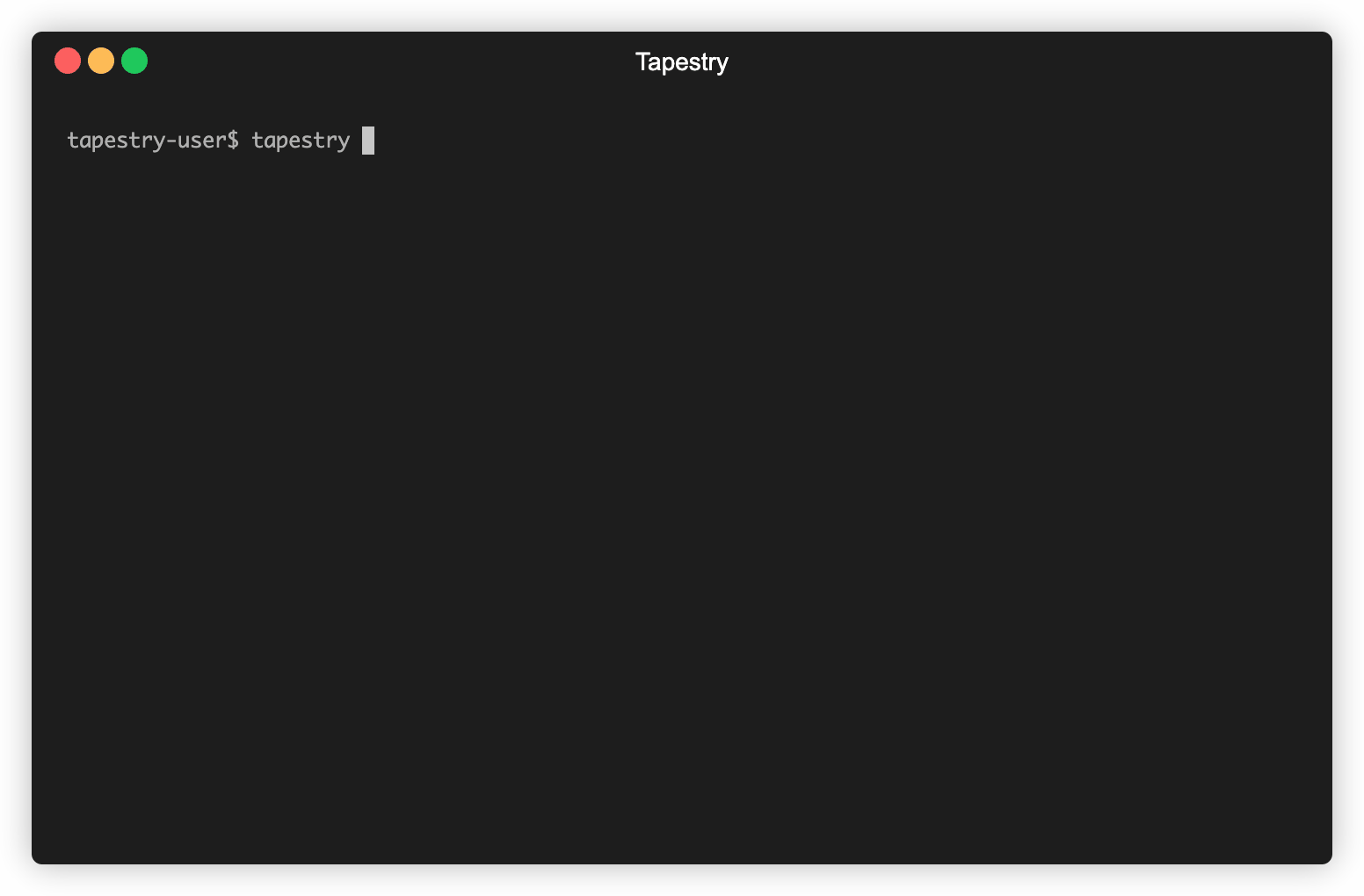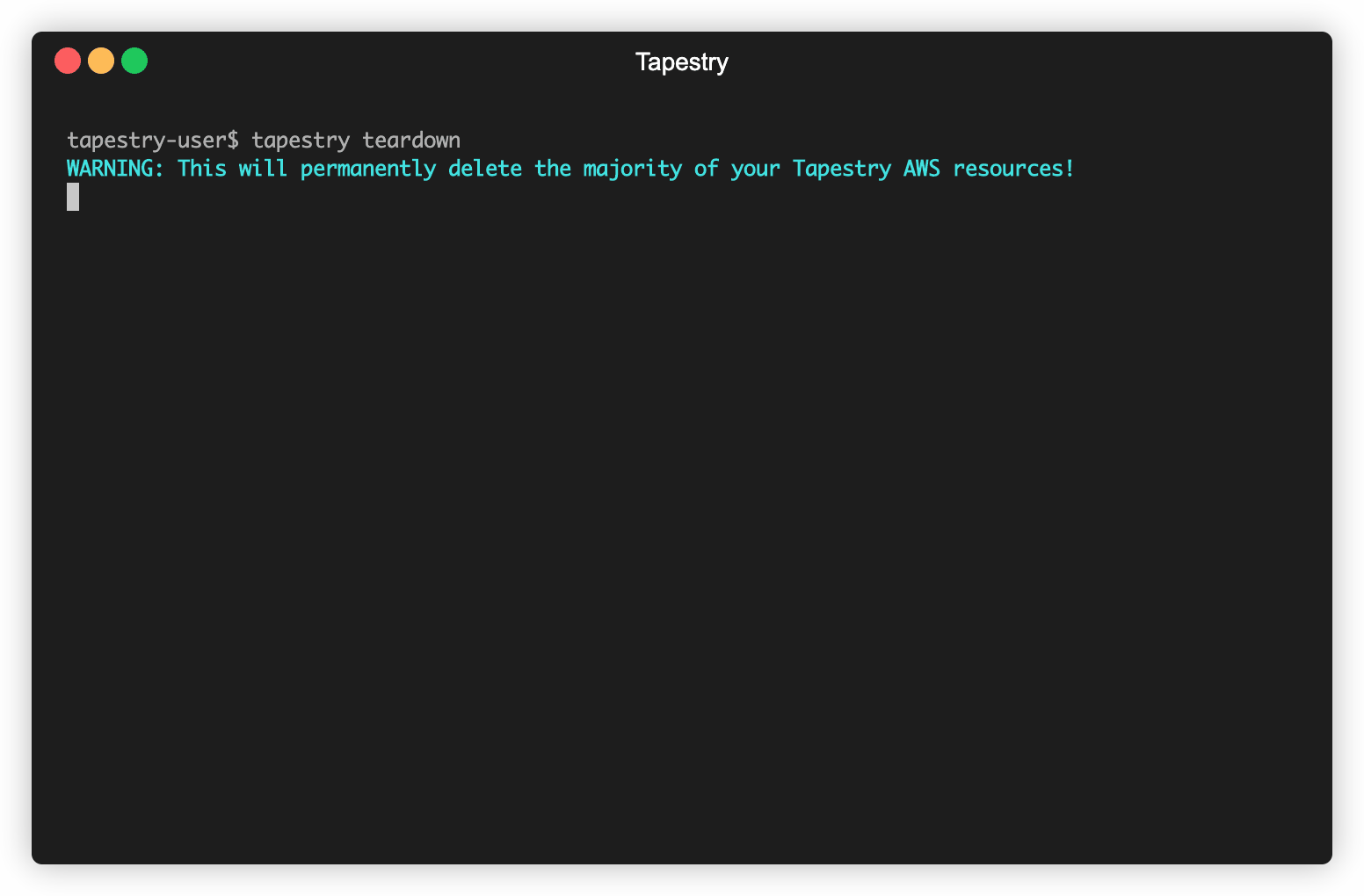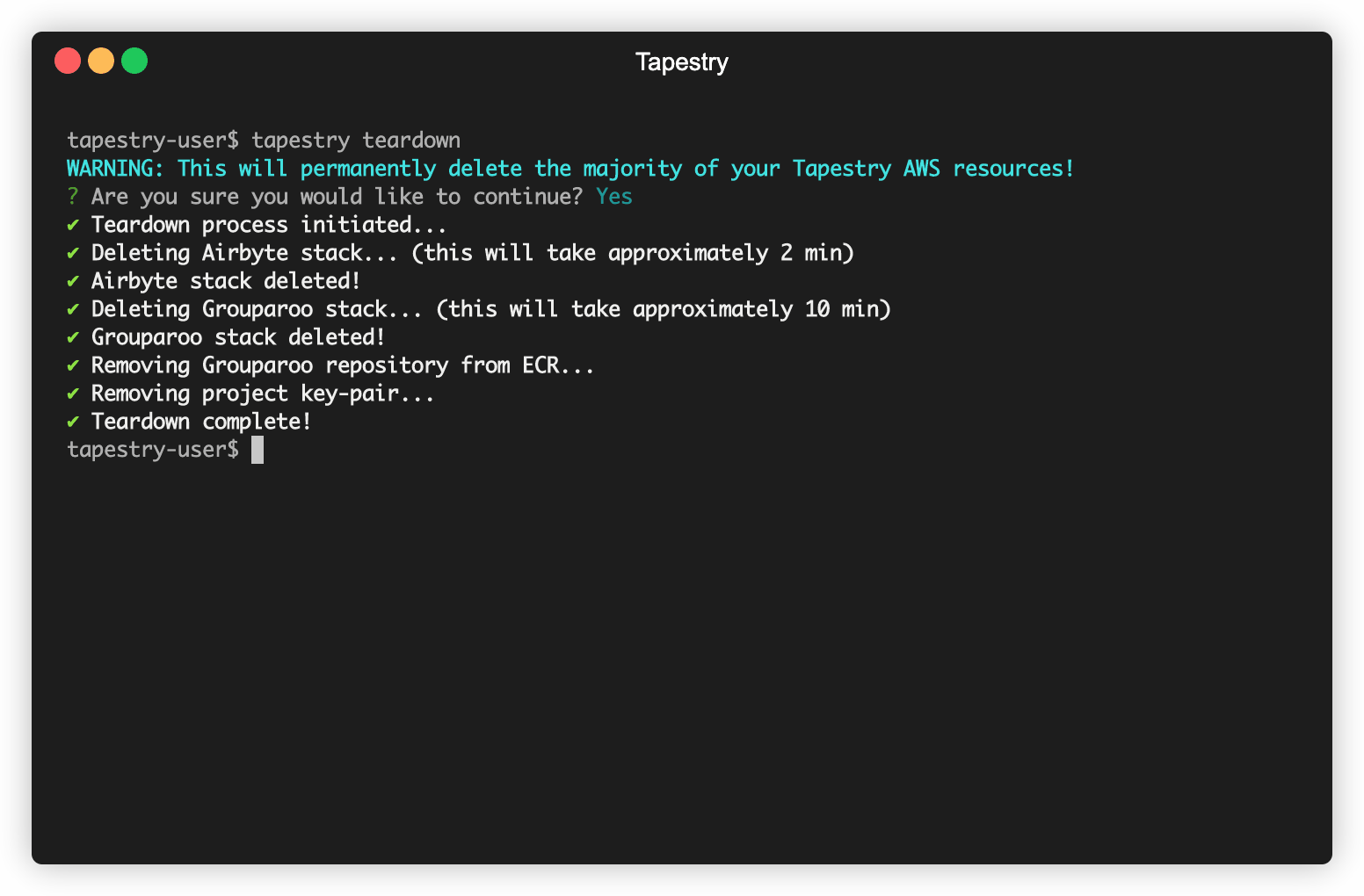
If the user, for whatever reason, decides they are no longer in need of Tapestry’s data pipeline, Tapestry
provides tapestry teardown to terminate and remove most of the AWS resources
provisioned during deployment, as well as the Airbyte and Grouparoo applications that ran on those resources.
We say “most” AWS resources because we do not destroy your S3 bucket, nor do we destory any parameters in your AWS SSM Parameter Store. Tapestry uses the Parameter Store to store user inputs, such as API keys and various account credentials. These resources remain intact so that you can retain access to this data even after your pipeline has been torn down.
6 Implementation Challenges
6.1 Ingestion Phase Challenges
Scaling the EC2 Instance
While prototyping the ingestion part of the pipeline, we encountered an interesting challenge. Initially, all of the Zoom data was being extracted and loaded into the data warehouse without any issues, but the Salesforce API call made by Airbyte was consistently timing out. This eventually led to a 504 server error.
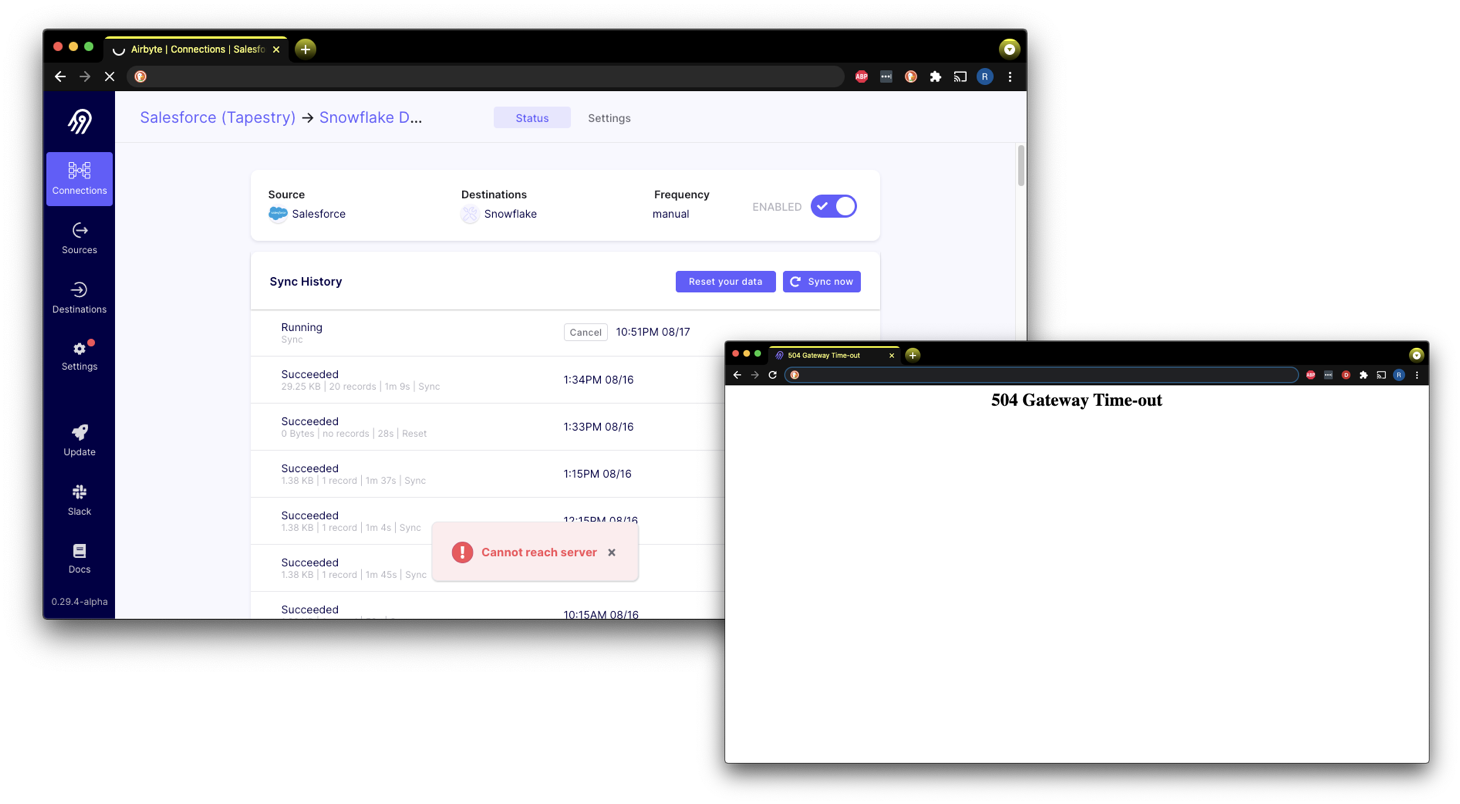
In AWS, we saw that the Airbyte EC2 Instance was becoming an unhealthy target for the Application Load Balancer every time we attempted to extract data from Salesforce through Airbyte.
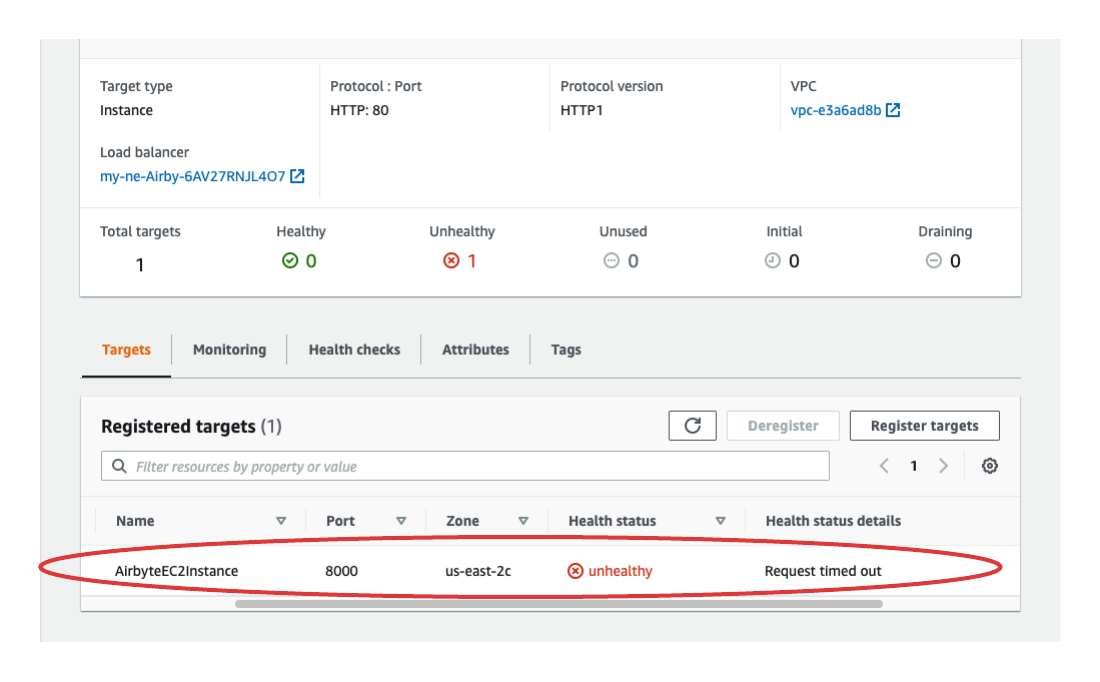
After further investigation, we found that the EC2 instance had alarmingly high CPU usage. Our solution was to
vertically scale this EC2 instance to increase its computing power. As we discussed
in our architecture section, we were limited to deploying Airbye on a single EC2 instance, making it
virtually impossible to horizontally scale. Once we increased the size of the server, our error message
disappeared.
This led to our decision to include a "CPU Utilization" section in Tapestry’s dashboard to monitor the AWS resources.
Caching an API Response
While we were implementing the automation of connecting Salesforce to the data warehouse, we were getting inconsistent
responses from API calls. When deploying each user's pipeline using the kickstart command,
Tapestry attempts to set up a connection between Salesforce and the user's warehouse through Airbyte. Ideally, the process is as follows:
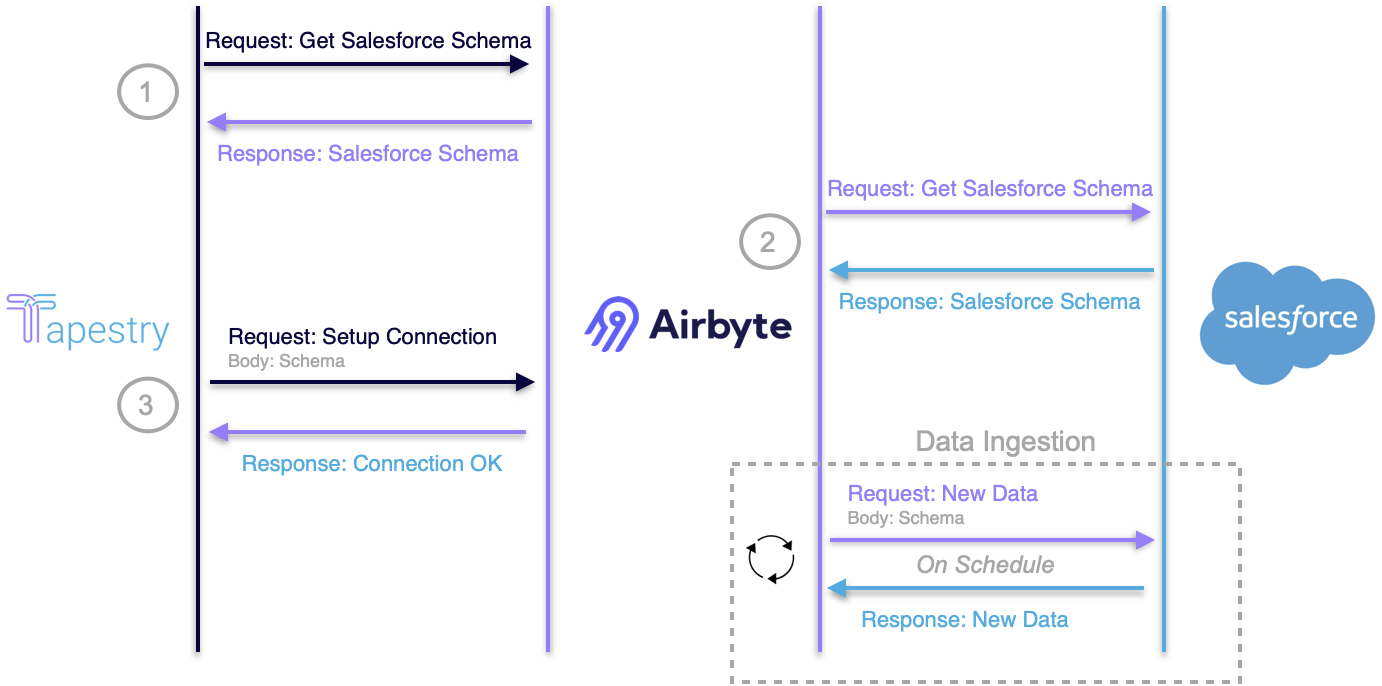
- Tapestry makes an API call to Airbyte to retrieve the appropriate schema for Salesforce contacts.
- Airbyte makes an API call to Salesforce to get the contacts schema and send that schema back to Tapestry.
- Tapestry makes another API call to Airbyte to set up a connection between Salesforce and the data warehouse (Snowflake).
The above process occurs once during deployment. If completed successfully, Airbyte makes API calls to Salesforce on the user's behalf to ingest data on a schedule. However, Airbyte did not always receive a successful response from Salesforce when requesting the schema. This, in turn, broke the rest of the process, and Tapestry was not able to establish the connection needed to begin transferring data.
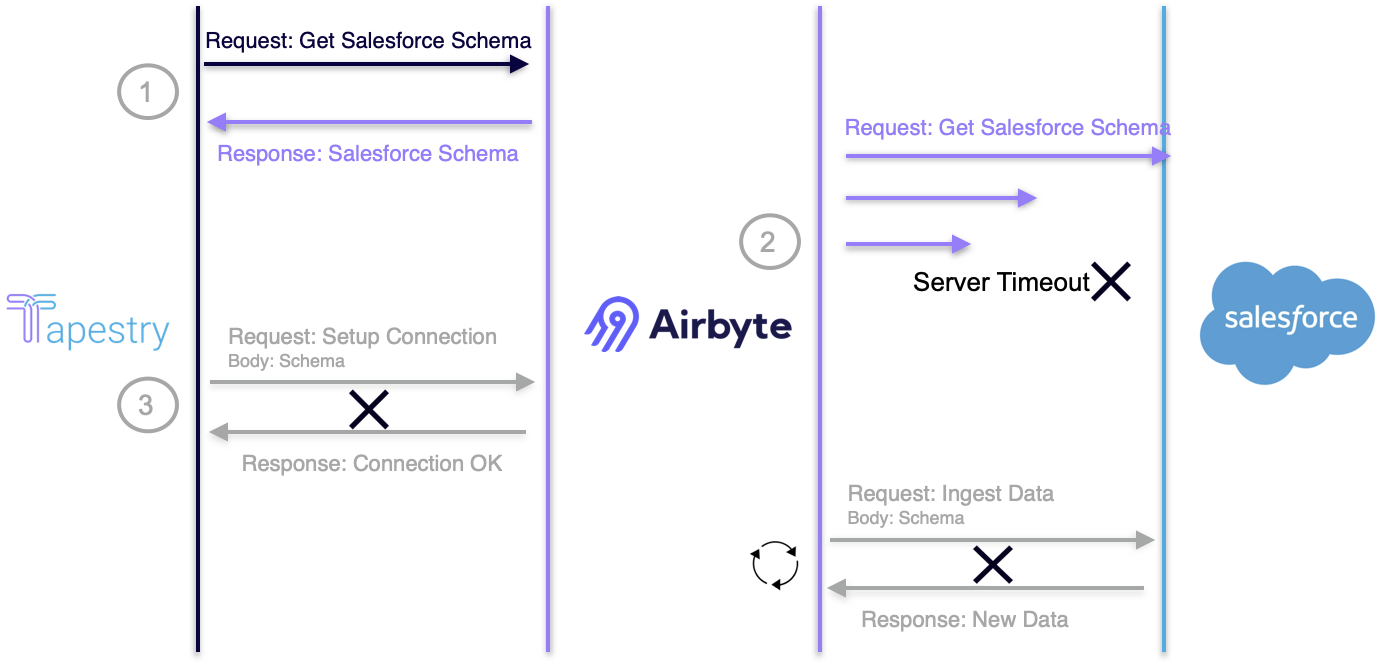
Upon further research, we found that Salesforce had an unreliable API endpoint, and that this was a common problem encountered by developers using Salesforce.
We couldn’t accept such an inconsistent response rate, so we considered two options:
- Implementing API retry logic
- Caching
Airbyte already has built-in retry logic that attempts the API call three times. In addition, we made multiple requests manually. This resulted in us hitting Salesforce’s rate limit and being throttled for a 24-hour period.
At that point, we could have tried exponentially backing off, but doing so would have made the user experience unacceptable. It would be an inconsistent experience, and would also potentially take hours before being able to ingest data.
So we turned to our next option, caching. We decided to store the Salesforce contact schema that we received from the next successful response in a file exporting a "contactSchema" object.
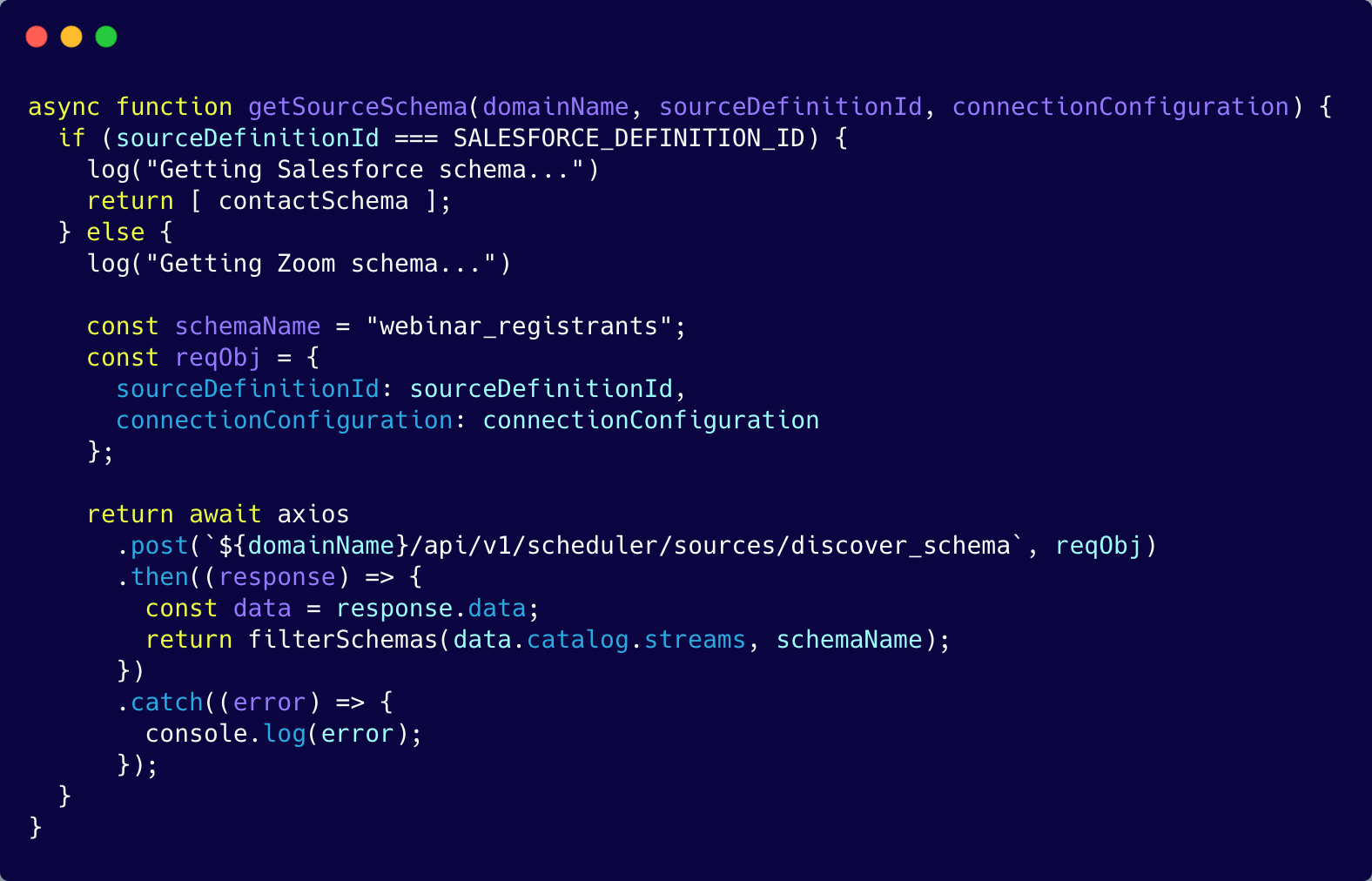
As the above image shows, we can now reference the "contactSchema" object for future API calls. This improved the process dramatically.
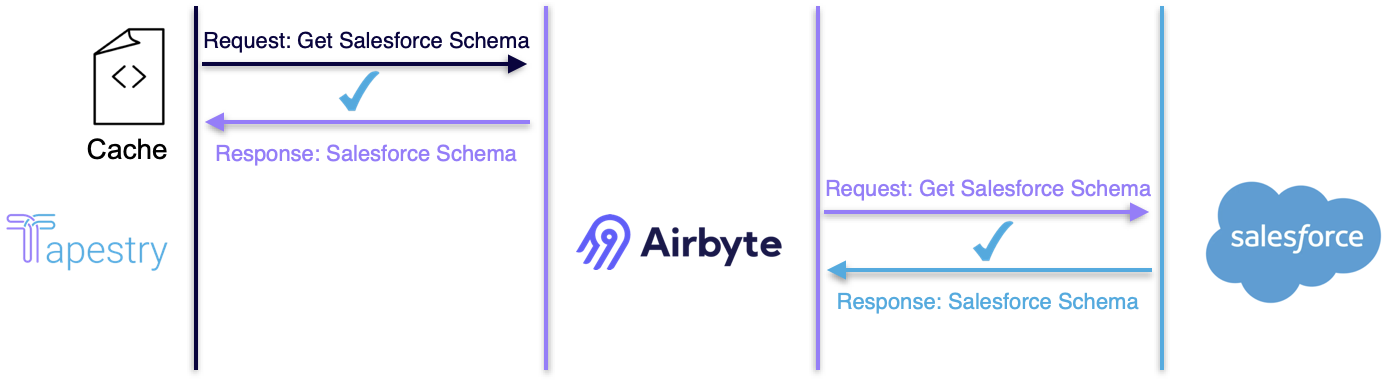
With the schema cached, we now only make one API call to establish the connection.
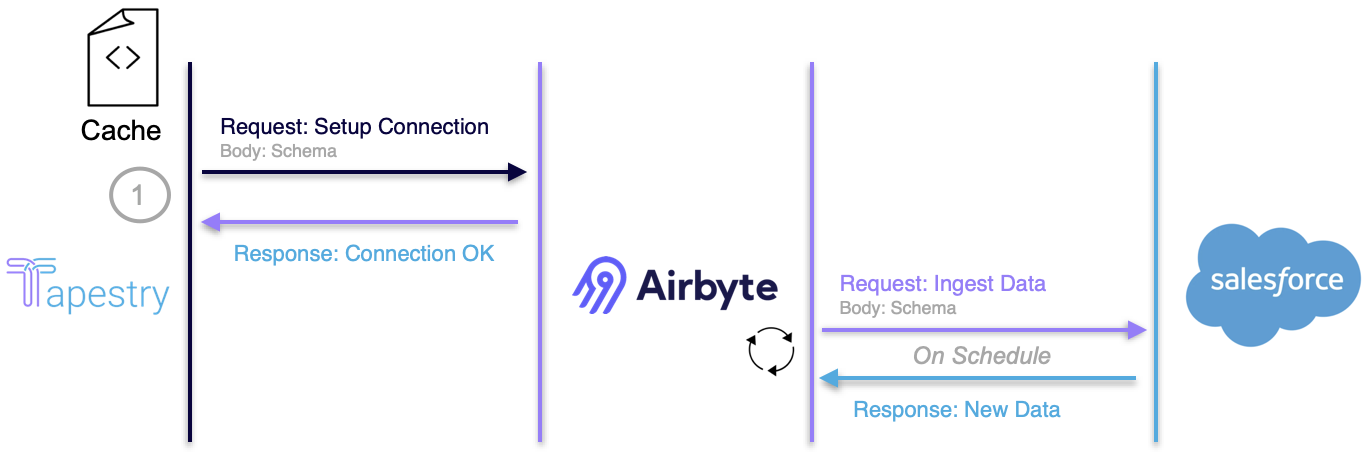
While this simplifies the overall deployment process, it's worth noting that this is not a permanent solution and comes with some drawbacks. If Salesforce ever makes a change to their schema, then our caching solution will break down. We would then need to capture the new schema and replace the old file with the new one. To us, though, this solution was worth the tradeoff of additional maintenance, and so far Salesforce has not made any changes to their schema.
6.2 Storage Phase Challenge
Automating Warehouse Setup
One interesting challenge we encountered when working with Snowflake was how to run SQL statements for a new user once they input their credentials. We needed to run a sequence of 34 commands to set up the warehouse with the necessary databases, schema, roles, and permissions for the Tapestry pipeline to operate.

Node.js SDK for Snowflake
We found that Snowflake provides a Node.js SDK, which would allow us to communicate with the Snowflake warehouse. Since the SDK only allows one SQL statement to be executed at a time, we needed to store each statement as an array element, and then iterate through each one individually.
Now that we could execute each SQL statement individually, we ran into another problem because the SDK is callback-based and runs code asynchronously.
To visualize this problem, we added a log statement with the array index, and you can see how the statements are being executed out of order. The error logs indicated that Snowflake was attempting to create databases and tables before the permission and role statements had finished executing.
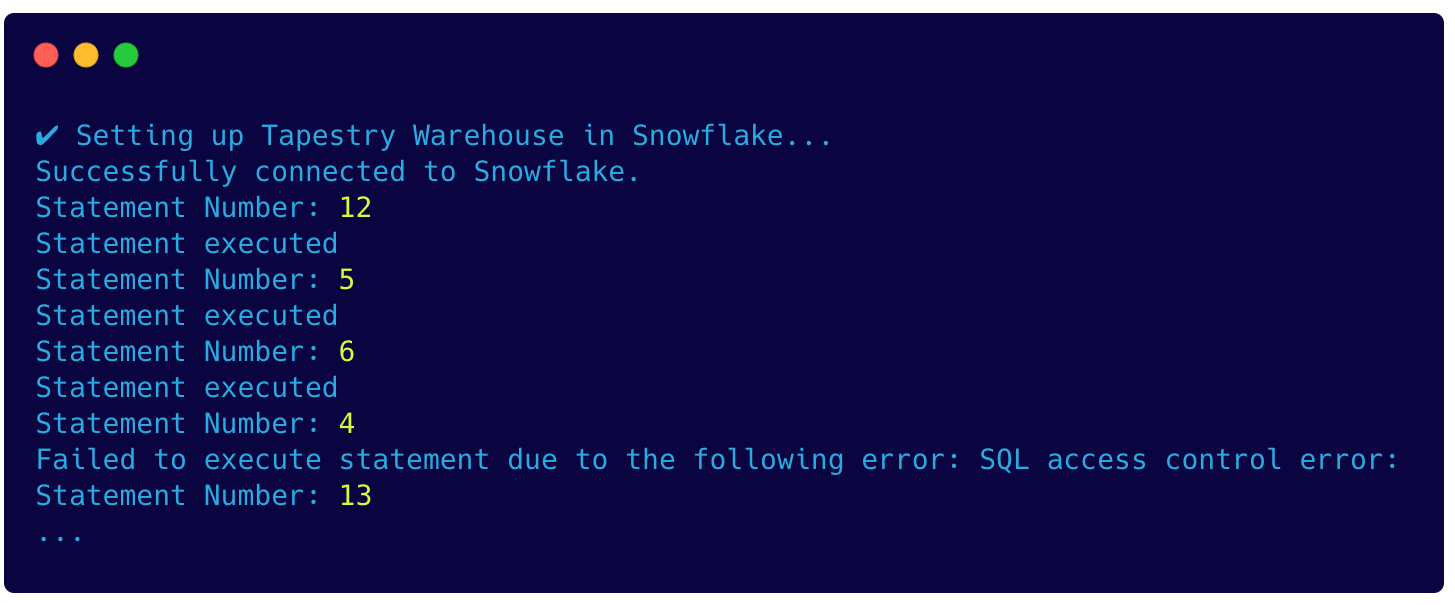
One option for solving this might be to nest each callback so that the statements are executed in the right order. However, this would result in unreadable code that would be hard to manage.
Snowflake Promise Library
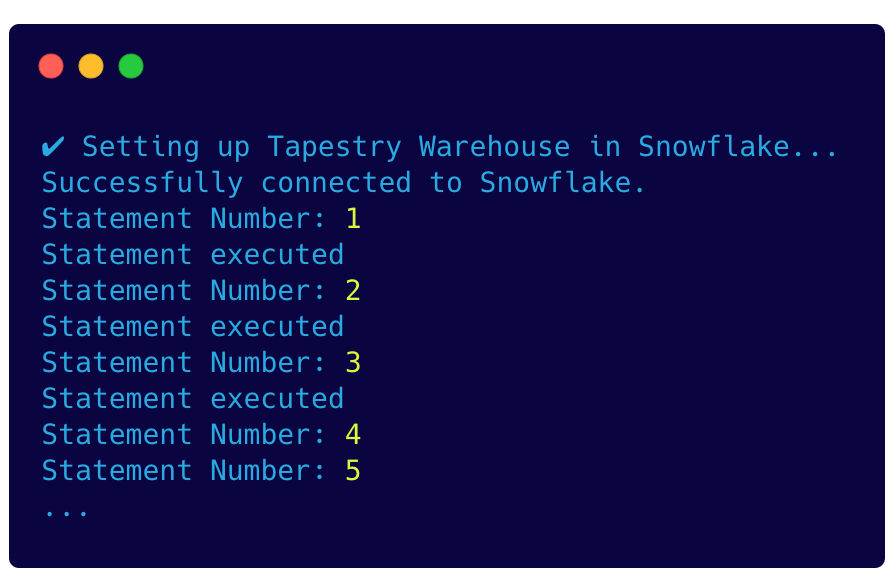
Instead, we opted to use the snowflake-promise library. This is a wrapper for the Snowflake SDK that provides a promised-based API.
This made it possible to use async/await to handle multiple promises in a synchronous fashion, and the logs indicate that the statements are being executed in the right order.
6.3 Syncing Phase Challenge
Injecting Secrets at Runtime
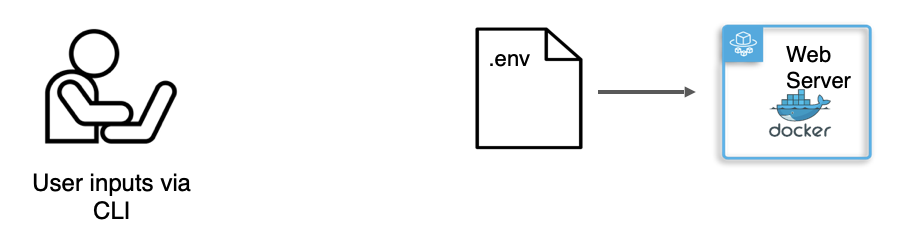
One particularly interesting challenge when deploying Grouparoo was determining how to inject sensitive user inputs, like API keys or passwords, into the Docker container for Grouparoo’s web application. For Grouparoo, we needed to reference these inputs in configuration files as environmental variables.

We soon learned that you can pass environmental variables to a container by referencing a local .env file within a Docker Compose YAML file. This solved part of the problem. The Docker container could now access any variables we provided in this file. However, since we do not receive user inputs until runtime, this .env file had to be dynamically generated during execution, but before running the container on ECS.
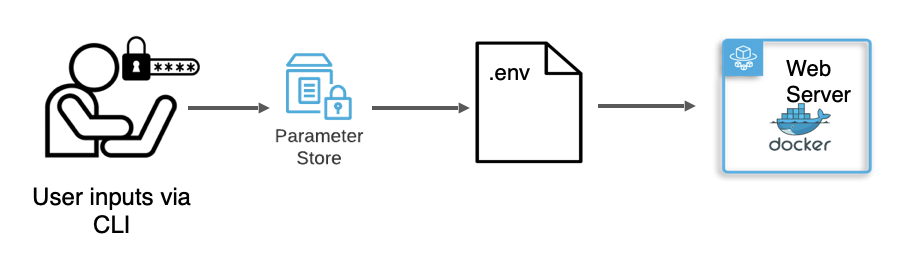
Our solution for doing this was two-fold. First, we stored the user inputs in the SSM Parameter Store on AWS. This ensured that this sensitive information was secure and encrypted, but also available for us to access from the AWS CLI as needed. Then, we created a function to dynamically write the .env file in the user’s project folder after we had all of their inputs.
7 Future Work
There are still a few features we would like to add to Tapestry in the future.
- Enable cross-platform support, such as deployment on Google Cloud Platform.
- Deploy Airbyte with ECS, so that our user has greater flexibility in terms of scaling. Airbyte has indicated that this compatibility will be available sometime in the future.
- Create more built-in templates to the kickstart command, so that Tapestry can be used out-of-the-box for more use cases.
- Incorporate more advanced metrics for pipeline monitoring, such as Cloudwatch alarms that can send notifications when particular utilization thresholds are reached.
8 References
Modern Data Pipeline:
- History of the Cloud Data Warehouse
- Emerging Architectures for Modern Data Infrastructure
- The Complete Customer Data Stack
- Modern Data Stack for Growth
Data Silos:
Reverse ETL/Syncing:
Companies:
Presentation
Team



